Read-Dominated Workloads
Contents
27.1. Read-Dominated Workloads#
There are many scenarios in operating systems and other concurrent software where certain data structures are frequently read, but rarely updated. For example, the OS caches network routing information, but route updates are infrequent compared to route lookups in the cache. Since read-only accesses cannot conflict with each other, we would like to allow “readers” to execute concurrently with each other (sharing access to the data structure), while “writers” must not be allowed to conflict with either readers or other writers. We will look at two ways to solve this problem: classical reader-writer locks (rw_locks), and read-copy-update (RCU).
27.1.1. Reader-Writer Locks#
Courtois et al. first described the reader-writer problem and two solutions using semaphores for mutual exclusion in 1971 [CHP71]. In the first version of the problem, readers have priority over writers: a reader thread should never be prevented from accessing the resource unless a writer has already been granted exclusive use of the resource. We show the solution for this reader-priority version in Listing 27.1 using POSIX semaphores. Note that since the semaphores are used only for mutual exclusion, we could replace them with pthread_mutex_t or any of our spinlock implementations without making any other changes. We represent access to some shared database with the read_db() and write_db() functions.
1static void read_db();
2static void write_db();
3
4sem_t mutex; /* Initially 1 */
5sem_t counter_mutex; /* Initially 1 */
6int reader_count = 0;
7
8static void writer()
9{
10 sem_wait(&mutex);
11 write_db();
12 sem_post(&mutex);
13}
14
15static void reader()
16{
17
18 sem_wait(&counter_mutex);
19 reader_count++;
20 if (reader_count == 1) {
21 /* first reader synchronizes with writers to acquire the resource */
22 sem_wait(&mutex);
23 }
24 sem_post(&counter_mutex);
25
26 read_db();
27
28 sem_wait(&counter_mutex);
29 reader_count--;
30 if (reader_count == 0) {
31 /* last reader releases the resource */
32 sem_post(&mutex);
33 }
34 sem_post(&counter_mutex);
35}
The writer code (lines 11-13) is very simple. We introduce a mutex semaphore (line 4) to protect access to the shared database. The wait on mutex at line 10 ensures that only one writer can be accessing the database at any time; when the writer is done, it posts a notice to mutex that the database is now available again (line 12). The reader code needs to do a little more work, however, because we want to allow multiple readers. First, we want to keep track of the number of readers currently accessing the database, so we introduce a reader_count variable (line 6), and since this variable will be updated by every reader thread, we also add a counter_mutex semaphore (line 5) to protect sections of code that depend on the reader_count. Each reader thread begins by waiting for the counter_mutex, then increments reader_count to add itself to the count of current readers (lines 18-19). Only the first reader thread needs to synchronize with writer threads (lines 20-23)—once a reader has successfully waited for the mutex, writers will be locked out until all the readers are done. Notice also that the first reader does not post to the counter_mutex until after it has obtained permission to access the database (line 24). This ensures that other reader threads must line up waiting for the counter_mutex as long as a writer is accessing the database; once the first reader obtains access to the database, the other readers only need to increment the reader_count. When a reader finishes using the database, it must again wait for the counter_mutex to subtract itself from the count of current readers (lines 28-29). When the reader_count falls to zero, it means that the last reader thread is done using the database, and this last thread must post a signal to the mutex to indicate that the database is available again (lines 30-33). If any writers are waiting, one will now be allowed to proceed; otherwise the database remains available until either a reader or writer threads requests access.
The reader code illustrates the lightswitch pattern in concurrent programming: the analogy is that the first person into a dark room turns on the light (acquires the resource), and the last one to leave turns it off (releases the resource).
We can encapsulate the entry sections of code (line 10 for writers; lines 18-24 for readers) and the exit sections of code (line 12 for writers; lines 28-34 for readers) into acquire and release functions for reader/writer locks. This code is shown in Listing 27.2:
1#include <semaphore.h>
2
3typedef struct rwlock_s {
4 sem_t mutex;
5 sem_t counter_mutex;
6 int reader_count;
7} rwlock_t;
8
9static inline void rwlock_init(rwlock_t *l) {
10 l->reader_count = 0;
11 sem_init(&l->counter_mutex, 0, 1);
12 sem_init(&l->mutex, 0, 1);
13}
14
15static inline void rwlock_acquire_write(rwlock_t *l)
16{
17 sem_wait(&l->mutex);
18}
19
20static inline void rwlock_release_write(rwlock_t *l)
21{
22 sem_post(&l->mutex);
23}
24
25static inline void rwlock_acquire_read(rwlock_t *l)
26{
27 sem_wait(&l->counter_mutex);
28 l->reader_count++;
29 if (l->reader_count == 1) {
30 /* first reader synchronizes with writers to acquire the resource */
31 sem_wait(&l->mutex);
32 }
33 sem_post(&l->counter_mutex);
34}
35
36static inline void rwlock_release_read(rwlock_t *l)
37{
38 sem_wait(&l->counter_mutex);
39 l->reader_count--;
40 if (l->reader_count == 0) {
41 /* last reader releases the resource */
42 sem_post(&l->mutex);
43 }
44 sem_post(&l->counter_mutex);
45}
We could combine the release functions and just have a single rwlock_release() function invoked by either reader or writer threads. When a writer releases the lock, the reader_count should already be 0; in that case we skip decrementing reader_count and just post to the mutex. This is the approach taken by the pthreads library implementation of reader/writer locks (man -k pthread_rwlock).
In this implementation of rwlocks, intensive read activity could starve writer threads. An alternative is to give writers priority: as soon as a writer thread requests access to the shared data, no new reader threads are allowed access until the writer is done using the data. The writer must still wait for existing reader threads to finish and release the data, but writers will not starve. If write activity is intense enough to worry about starving readers, then rwlocks are probably not a good choice anyway.
27.1.2. Performance of Reader/Writer Locks#
To be added.
Takeaway: The reader side of reader/writer locks is expensive, since an internal lock must be acquired and released on every rwlock_acquire_read and rwlock_release_read to modify the reader_count and check if the current thread is either the first (on acquire) or last (on release) reader. For short read-side critical sections, the overhead of rwlocks can overwhelm the benefit of allowing readers to access the shared data structure concurrently with each other.
27.1.3. Read-Copy Update#
Read-Copy Update (RCU) is an alternative reader/writer synchronization mechanism designed for read-mostly data structures. Readers use no locks at all, thereby addressing the read-side overhead of rwlocks. Writers only need to synchronize with other writers, typically by using ordinary locks. Thus, RCU lets multiple readers access data concurrently with one writer. The key property we need to ensure is that readers always see a consistent version of the data, either before a writer performs an update, or after the update is complete. To achieve this, writers must create new versions of the data atomically, for example, by making a copy of a node in a data structure that they want to update, performing the update on the copy, and atomically replacing the old copy with the new copy into the data structure. Concurrent readers can continue to access the old version of the data; new readers will see the update. Of course, the old version must be deleted at some point, but only after we are able to guarantee that no reader can be accessing it.
Unlike with reader/writer locks, RCU readers can read stale data and may see inconsistencies (for example, an RCU reader counting the number of items in a linked list might return a total that would not be possible under reader/writer locking). However, there are many situations where this staleness and inconsistency doesn’t matter. Paul McKenney uses the example of the network routing table in one of his RCU LWN article:
Because routing updates can take considerable time to reach a given system (seconds or even minutes), the system will have been sending packets the wrong way for quite some time when the update arrives. It is usually not a problem to continue sending updates the wrong way for a few additional milliseconds.
Although RCU readers use no locking, we still need to reason about reader accesses to shared data, to determine when it is safe for a writer to reclaim memory. Thus, we refer to the sections of code where readers are accessing a shared data structure as a read-side critical section, and we impose some restrictions on what threads are allowed to do in a read-side critical section.
We will present RCU with reference to the Linux kernel implementation. An excellent resource for further reading on this topic can be found in the [Linux kernel documentation of RCU]https://www.kernel.org/doc/html/latest/RCU/whatisRCU.html.
27.1.3.1. Why RCU?#
Before we dive into RCU and how it works in more detail, we will motivate the RCU approach using the example of a concurrent hash table, as depicted in Fig. 27.1. Such data structures are widely used in operating systems, for example to build caches of network routing information or file system metadata, and to locate data structures like the thread structure given a key like the thread identifier. To look up a key in the hashtable, a hash function selects a bucket (i.e., an entry in an array). Collisions are handled by chaining, so once we have found the right bucket, we will need to search the linked list of items that hash to the same bucket. Since the hashtable can be accessed by multiple threads concurrently searching for items, inserting new items, or deleting items, we will need some synchronization. Rather than a single lock on the entire hashtable, we can increase concurrency by using a separate lock for each bucket in the hashtable. Because each bucket has its own lock, we can simplify the scenario by just thinking about concurrent operations on a linked list; operations that hash to different buckets will not conflict with each other.
Fig. 27.1 Concurrent hashtable with per-bucket locking.#
For read-mostly workloads, where searches are much more frequent than insertions, deletions, or updates, we might want to use a rwlock on the hash buckets, but these have a lot of overhead for readers. Even ignoring the cost of the locks themselves, forcing all readers to wait so that a writer can have exclusive access may leave us with lots of “dead time” as depicted in Fig. 27.2.
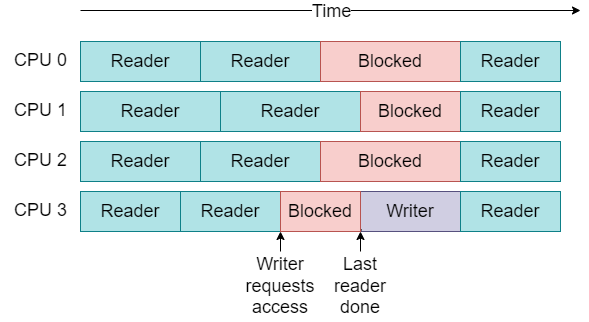
Fig. 27.2 A single writer can block many readers with rwlocks.#
Ideally, readers would never have to wait for writers, so that this wasted time could be eliminated, as depicted in Fig. 27.3.
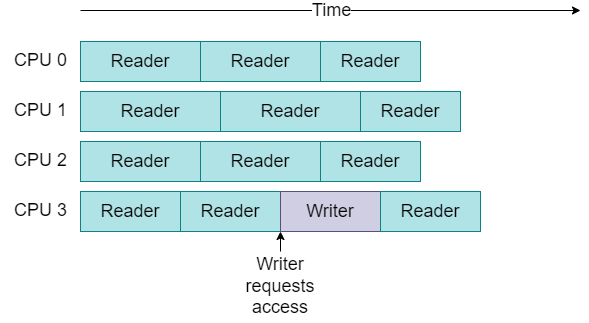
Fig. 27.3 A writer does not wait for readers to finish, and does not block readers.#
In Section 26.3.4, we mentioned non-blocking synchronization as a way to break the mutual exclusion condition, and noted that there were non-blocking implementations of linked lists. We could certainly use a non-blocking linked list in our concurrent hash table, which would eliminate the stalls in Fig. 27.2, but this still introduces more overhead than we would like, even if the workload is entirely read-only. To see why, consider what happens if there is a concurrent lookup and delete operation on a linked list. We show this scenario in Fig. 27.4.
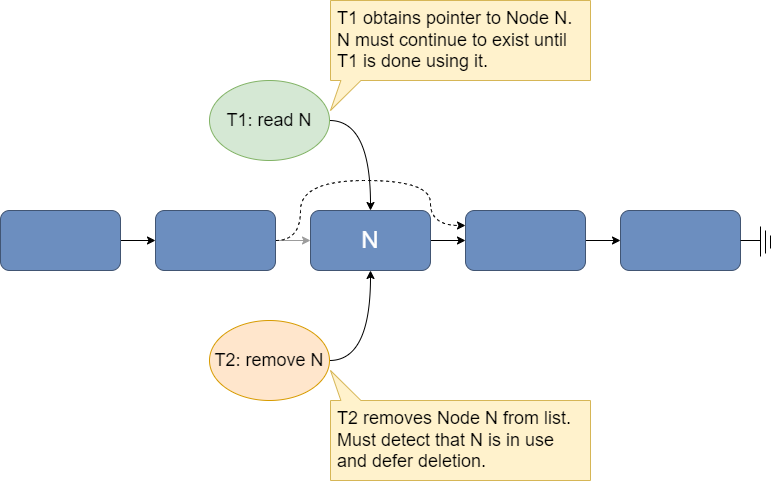
Fig. 27.4 Concurrent read and removal of an element in a linked list.#
Here, a reader thread T1 is traversing the linked list and has obtained a pointer to node N (e.g., by reading the previous node’s next field). T1 still needs to read several fields from node N (e.g., the key, to see if it is the one it is searching for, and the value if the key matches, or the next pointer to continue the search if the key does not match). At some point after T1 has a pointer to N, a writer thread T2 deletes N from the linked list. Removal from the list can be done atomically by changing the previous node’s next field to point to the node that follows N (shown by the dotted line in the figure). However, T2 cannot reclaim the memory used by node N until it can guarantee that T1 no longer holds a pointer to it.
Reference counting is the common solution to guarantee the continued existence of a node as long as a thread needs it. Each node includes an integer reference count, and each thread must atomically increment the reference count when it gets a pointer to the node, and atomically decrement the reference count when it is done with the node. A node that is removed from the linked list can be reclaimed when the removing thread holds the last reference to it. Thus, as T1 traverses the list, it must perform two atomic operations on every node that it visits just to guarantee that the node doesn’t disappear out from under it (see Fig. 27.5). Worse, all reader threads need to atomically change the reference counts, even if there aren’t any writers operating concurrently! Atomic arithmetic operations are much more expensive than an ordinary addition or subtraction operation because they must modify memory (not a CPU register), and they limit the ability to hide the cost of memory access by re-ordering other instructions. As a result, reference counting can have a surprisingly high overhead.
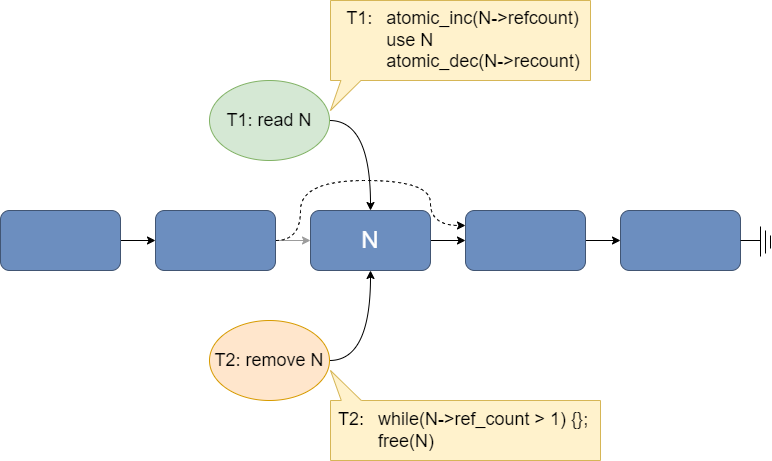
Fig. 27.5 Concurrent read and removal of an element in a linked list with reference counting.#
RCU has the same problem of deferred deletion, but it avoids the use of reference counting, so that no extra work is imposed on readers. The tradeoff is that writers need to do more work, but this is reasonable since we are expecting a read-mostly workload.
27.1.3.2. The read-side#
The Linux RCU API requires programmers to mark the boundaries of a read-side critical section with rcu_read_lock() and rcu_read_unlock() calls. Reader threads are not allowed to block in an RCU read-side critical section, and are not allowed to use any pointer to rcu-protected shared data outside of a read-side critical section. In spite of the names, these API calls do not actually lock anything. In a non-preemptible kernel build environment, they are simply empty macros that do nothing at all. For a pre-emptible kernel, the rcu_read_lock() call simply needs to disable preemption, while the rcu_read_unlock() call re-enables it. This ensures that readers can complete their critical sections without losing the CPU to any interfering threads. Even in a non-preemptible kernel, marking the boundaries of read-side critical sections with an API call is useful, as it helps programmers to reason about their code and avoid violating the requirements of read-side critical sections.
27.1.3.3. The write-side#
RCU writers can use any mechanism to synchronize with other writers, but typically an ordinary mutual exclusion lock is used, because updates are expected to be relatively infrequent and so contention on the writer lock is expected to be low. Writers carry out their updates in two phases:
The removal phase may atomically remove items from a data structure. These removals may occur due to either updates or deletions from the data structure. In the case of an update, the removed item is replaced with a reference to a new version of the item. Note that the removal phase may also insert completely new items to the data structure, without removing anything, in which case the second phase is not needed.
The reclamation phase frees the memory used by the removed items.
The removal phase runs concurrently with readers, so readers that are active in a read-side critical section during this phase might still be using the removed items. To avoid use-after-free bugs in the readers, a writer must wait for a grace period between the removal and reclamation phases, after which there is a guarantee that all readers that were active during the removal phase no longer hold references to these items. Any readers that start after the removal phase can’t possibly obtain a reference to the removed items, so we don’t need to consider them. We show an example of this split update approach in Fig. 27.6. Readers that are still active in their read-side critical section at the end of the removal phase are depicted with cross-hatches. The writer must wait until all of these pre-existing readers have left their read-side critical sections and can no longer make any references to the removed data. After this grace period, the writer can reclaim the memory allocated for the removed item. Readers that enter their read-side critical section during the grace period, or during the reclamation phase, do not need to be waited for.
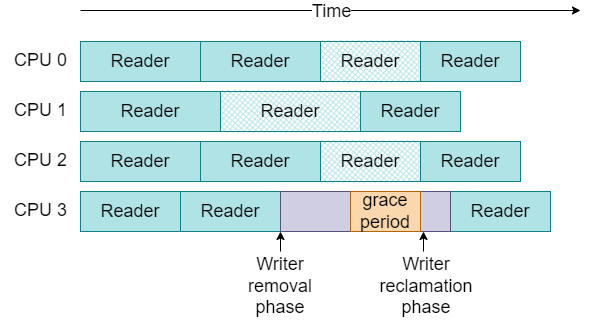
Fig. 27.6 Updates are split into removal and reclamation phases, separated by a grace period.#
An example of the writer side for an RCU-protected data structure is shown in Listing 27.3. In this example, we have a global pointer to shared struct foo, which consists of three fields. We also have a spinlock foo_mutex for writers, to ensure there is at most one update happening at any time. The writer thread calls foo_update_a to update the a field with a new value, new_a. In this function, we first allocate memory for a new copy of the structure (line 16, kmalloc is just the kernel version of the C library malloc function), then (under the protection of the writer lock) we make a copy of the current structure, update the a field, and make the new version of the structure visible to other threads by setting the global shared_foo pointer to the new copy (lines 17-21). At this point, the removal phase of the update is complete and we can release the writer lock (line 22). The writer must wait for a grace period before it can free the memory allocated to the old copy of the structure, which it does by calling the Linux synchronize_rcu() function (line 25). Finally, the memory is freed (line 28) and the function returns.
1struct foo {
2 int a;
3 char b;
4 long c;
5};
6
7spinlock_t foo_mutex;
8struct foo *shared_foo;
9
10void foo_update_a(int new_a)
11{
12 struct foo *new_fp, old_fp;
13
14 /* 1. Removal phase */
15
16 new_fp = (struct foo *)kmalloc(sizeof(struct foo), ...);
17 lock(&foo_mutex);
18 old_fp = shared_foo;
19 *new_fp = *old_fp;
20 new_fp->a = new_a;
21 shared_foo = new_fp;
22 unlock(&foo_mutex);
23
24 /* Removal phase done. Wait for a grace period */
25 synchronize_rcu();
26
27 /* 2. Reclamation phase */
28 kfree(old_fp);
29}
The code in Listing 27.3 is a simplified example. It assumes that instructions cannot be re-ordered by either the compiler or the CPU at runtime; the full Linux RCU API includes operations to enforce the required ordering when reading or writing rcu-protected pointers. Now, let’s look at what happens in the synchronize_rcu() function to ensure there are no dangerous read-reclaim races.
27.1.3.4. Handling read-reclaim races#
The challenge in handling read-reclaim races lies in detecting when a grace period has elapsed. We cannot use actual time to define a grace period, since we do not know how long readers will stay in a read-side critical section. We also don’t want the readers to do any extra work to help detect grace periods, as happens with reference counting, or at least keep the reader overhead to a bare minimum.
RCU uses quiescent state based reclamation (QSBR) [HMBW07] to detect grace periods and determine when it is safe to reclaim a removed item. We define a quiescent state for a thread T as a state in which T holds no references to rcu-protected shared data. We can then define a grace period as an interval in which every thread has entered at least one quiescent state, as shown in Fig. 27.7. Essentially, this means that we do not need to be concerned with tracking every reference to shared data from every thread—we just need to track quiescent states.
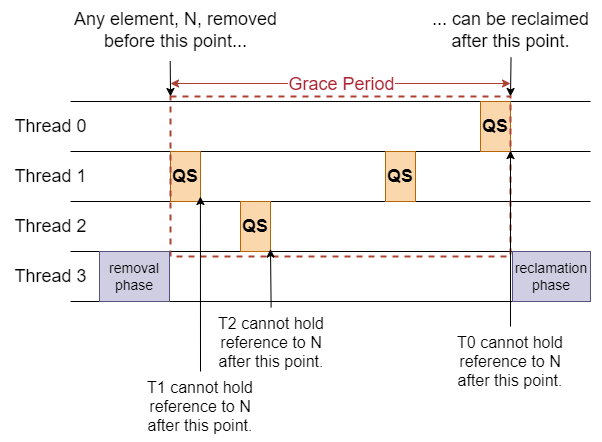
Fig. 27.7 Illustration of quiescent state based reclamation. Grace periods occur when every thread has gone through a quiescent state.#
But how can we know that a thread is in a quiescent state if we are not keeping track of its references to shared data? Recall that reader threads are not allowed to use any pointer to rcu-protected data outside of a read-side critical section. So, whenever a reader thread is not in a read-side critical section, it is in a quiescent state. Recall also that readers in a read-side critical section cannot block or be preempted. These properties are a great help in detecting grace periods in an operating system kernel. First, any thread that is not running on a CPU at the end of a writer’s removal phase must already be in a quiescent state and we don’t need to consider them any further. Second, for all threads that are running on a CPU at the end of the writer’s removal phase, they must be in a quiescent state when a context switch occurs (i.e., context switches, whether due to blocking or preemption, are not allowed in a read-side critical section). Thus, the synchronize_rcu() function only needs to wait until all other CPUs perform a context switch to be sure that a grace period has elapsed. Conceptually, this can be done by having the writer thread run some code in the synchronize_rcu() function on every CPU. If the writer is able to run on every CPU, then a context switch must have occurred on every CPU, and every reader thread has entered at least one quiescent state. A sketch of the code for this “toy” implementation is shown in Listing 27.4.
1void synchronize_rcu(void)
2{
3 int cpu;
4
5 for_each_possible_cpu(cpu)
6 run_on(cpu);
7}
Of course, there are many details of a robust, scalable, RCU implementation that we have glossed over in this quick introduction. Interested readers are encouraged to refer to the Linux kernel documentation and source code.
The use of RCU in Linux has been growing steadily, as shown in Fig. 27.8, however, it is not a suitable replacement for every synchronization need. Uses of the lock APIs in Linux still far outnumber RCU (see Fig. 27.9).
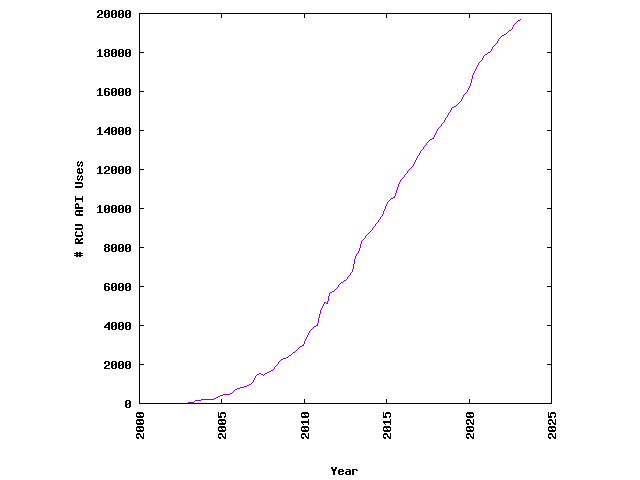
Fig. 27.8 Growth of RCU usage in the Linux kernel (from http://www.rdrop.com/~paulmck/RCU/linuxusage.html, April 25, 2023)#
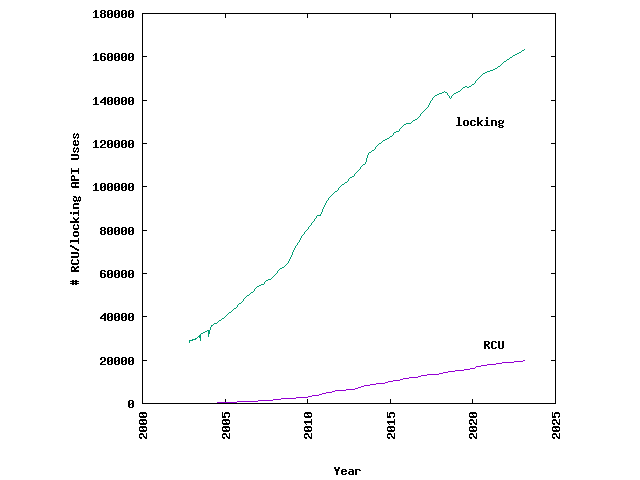
Fig. 27.9 Linux RCU and lock usage (from http://www.rdrop.com/~paulmck/RCU/linuxusage.html, April 25, 2023)#