Disk Layout:Tracking Used Space
Contents
22.2. Disk Layout:Tracking Used Space#
The main job of the file system is to use the blocks on the disk to store persistent data for users in files, and to support the organization of those files into directories. Clearly, we will need a way for the file system to keep track of which blocks are being used for each file. In this Chapter, we will explore several options for this important design decision.
Note that in many (most? all?) file systems, directory objects (which hold file system metadata about the files in that directory) are stored exactly like files. Part of the information the file system keeps about each object is a type field, which allows the file system to distinguish file objects from directory objects. While the content of file objects is only understood by the applications that use them (above the file system), the content of directory objects is understood and managed by the file system itself. Everything we say here about techniques for keeping track of the blocks used by files also applies to the task of tracking blocks used by directories.
22.2.1. Contiguous#
The simplest organization of a file system is to just have each file or directory occupy a contiguous set of blocks on the disk. For example, Fig. 22.3 shows a structure similar to early versions of the ISO-9660 file system for CD-ROM disks. Objects on disk are either files or
directories, each composed of one or more 2048-byte blocks; all
pointers in the file system are in terms of block numbers, with blocks
numbered from block 0 at the beginning of the disk or partition. Note that the len field in Fig. 22.3 gives the file length in bytes, not blocks, but space in the file system must be allocated in block-sized chunks. The number of blocks used by the file can be calculated as the ceiling of the file size divided by the block size, i.e., \(\lceil len / 2048 \rceil\) in this example.
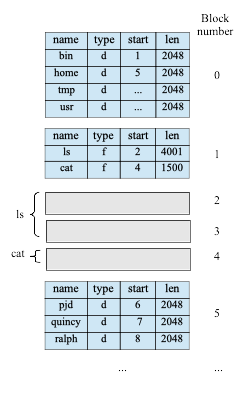
Fig. 22.3 Simplified ISO-9660 (CDROM) file layout for tree in Fig. 20.1, 2 KB blocks#
The advantages of this approach are:
Very dense meta-data, you can represent all the blocks used by a file system with one record having a starting block number and a length.
Very fast reads, you only need to do one seek operation to get to all the blocks of any file on the disk.
Contiguous organization works fine for a read-only file system, where all files (and their sizes) are available when the file system is created. It, however, works poorly for writable file systems because:
File system space becomes rapidly fragmented, making it impossible to create large files.
There is no way to add information to a file without reading it and writing it as a new file. Appending to a file may be possible, if the blocks that follow the end of the file are not being used by another file, but in general this will not be the case.
22.2.2. Linked list#
Another approach to keep track of the blocks used in a file is to maintain a linked list as shown in Fig. 22.4. This approach doesn’t have the external fragmentation challenge of contiguous files, because any available block can be used to add more data to any file by simply adding the block to the list.
The top part of Fig. 22.4 uses internal pointers in a block, where each block stores slightly less than a full block of data to make room for the pointer metadata. This approach might seem attractive, however, it is not practical for several reasons. First, to read the block containing data at a particular offset in a file, one has to read blocks sequentially through the entire linked list up to the required block. Second, mixing file data with file system metadata in the same block would add complexity to operating system features like memory-mapped files. We won’t be in a position to explain why this is the case until we cover memory management, however. Finally, because the amount of data stored in a block is no longer a power of 2, calculating the block that contains a given offset will require integer division operations, rather than cheaper right-shift operations.
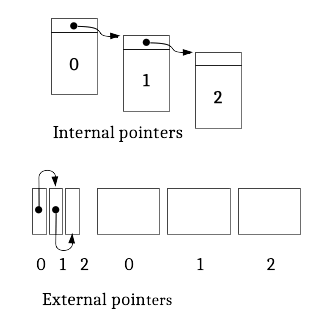
Fig. 22.4 Linked list organization with in-object pointers (typical for in-memory structures) and external pointers, as used in MS-DOS File Allocation Table.#
An alternative (shown in the bottom of Fig. 22.4) would store the pointers of the linked list in a separate array from the disk blocks themselves. This is used in the MS-DOS (or FAT, File Allocation Table) file system. Block numbers are kept in a separate array, with an entry corresponding to each disk block, in what is called the File Allocation Table.
Entries in this table can indicate (a) the number of the next block in the file or directory, (b) that the block is the last one in a file or (c) the block is free. The FAT is thus used for free space management as well as file organization; when a block is needed the table may be searched for a free entry which can then be allocated.
Access to a file incurs overhead to fetch file allocation table entries, although since these are frequently used they may be cached in memory; random access to a file, however, requires walking the linked list to find the corresponding entry, which can be slow even when cached in memory. However, if a file is distributed across the disk performance can be terrible. Consider random I/O within a 1 GB virtual disk image with 4 KB blocks—the linked list will have 256 K entries, and on average each I/O will require searching halfway through the list.
22.2.3. Inode#
File systems derived from the original Unix file system use a per-file structure called an inode to not only keep track of attributes, but also block locations. The inode uses an asymmetric tree, or actually a series of trees of increasing height with the root of each tree stored in the inode.
As seen in Fig. 22.5 the inode contains N direct block pointers (12 in ext2/ext3), so that files of N blocks or less need no indirect blocks. A single indirect pointer specifies an indirect block, holding pointers to blocks \(N, N+1, ... N+N_1-1\) where \(N_1\) is the number of block numbers that fit in a file system block (1024 for ext2 with a 4 KB blocksize).
If necessary, the double-indirect pointer specifies a block holding pointers to \(N_1\) indirect blocks, which in turn hold pointers to blocks \(N+N_1 ... N+N_1+N_1^2-1\)—i.e. an \(N_1\)-ary tree of height 2; a triple indirect block in turn points to a tree of height 3.
For ext2 with 4-byte block numbers, if we use 4K blocks this gives a maximum file size of \((4096/4)^3\) 4 KB blocks, or 4.004 TB. This organization allows random access within a file with overhead \(O(logN)\) where \(N\) is the file size, which is vastly better than the \(O(N)\) overhead of the MS-DOS File Access Table system.
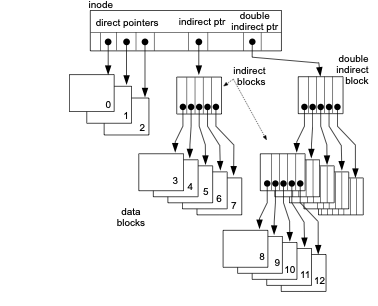
Fig. 22.5 Inode-type file organization as found in many Unix file systems (e.g. Linux ext2, ext3)#
Inode structures are a reasonable compromise, they have (a) low overhead for small files, in terms of both disk seeks and allocated blocks, and (b) ability to represent sufficiently large files without excessive storage space or performance overhead.
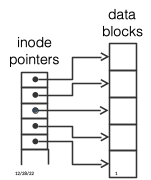
Fig. 22.6 File structure—pointers#
22.2.4. Extents#
The ext2 and MS-DOS file systems use separate pointers to every data block in a file, located in inodes and indirect blocks in the case of ext2, and in the File Allocation Table in MS-DOS. However, a well-designed file system will attempt to allocate blocks to files sequentially to avoid disk seeks —if the first block in a file is block 100, it’s highly likely that the second will be 101, the third 102, etc.
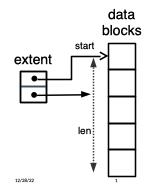
Fig. 22.7 File structure— extents#
We can take advantage of this to greatly compress the information needed to identify the blocks in a file - rather than having separate pointers to blocks 100,101,…120 we just need to identify the starting block (100) and the length (21 blocks). This is shown in Fig. 22.6, where five data blocks are identified by direct pointers in an inode. In Fig. 22.7, the same five data blocks are identified by a single extent. Why would we want to compress the information needed to organize the blocks in a file? Mostly for performance—although the code is more complicated, it will require fewer disk seeks to read from disk.
This organization is the basis of extent-based file systems, where blocks in a file are identified via one or more extents, or (start,length) pairs. The inode (or equivalent) can contain space for a small number of extents; if the file grows too big, then you add the equivalent of indirect blocks - extents pointing to blocks holding more extents. Both Microsoft NTFS and Linux ext4 use this sort of extent structure.