Scheduling in the real world
Contents
10.4. Scheduling in the real world#
We briefly review some of the real world scheduling issues and approaches from a Linux perspective.
10.4.1. Multi-CPU scheduling#
Today almost all systems have multiple CPUs. Early multi-CPU systems looked something like Fig. 10.10 below. If you compare with the simple computer picture we showed in the past (Fig. 2.1), there are just a modest number of CPUs accessing both the memory and I/O buses.
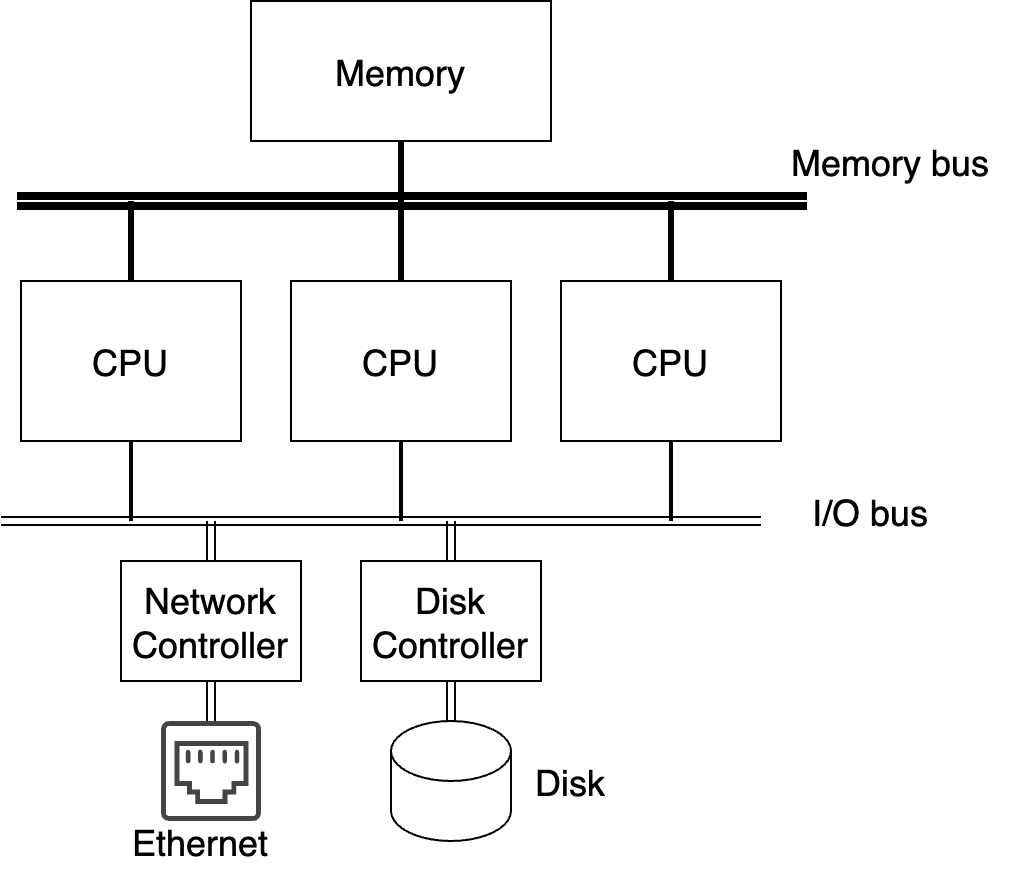
Fig. 10.10 Early multiprocessors#
The easiest solution, and the one first adopted by most operating systems to support these computers, was to have a single runqueue in the kernel. This is both simple, and fair, since whatever algorithm you apply for scheduling selects the best task to run irrespective of which CPU becomes available.
Unfortunately, today’s systems look more like Fig. 10.11. They have memory controllers and I/O controllers in sockets, which is really just a processor chip. The sockets have a large number of CPUs (or cores) each with their own caches, and a shared cache per socket. Memory is directly attached to one of the sockets, and all accesses from other sockets have to go through it; leading to Non-Uniform Memory Access (NUMA).
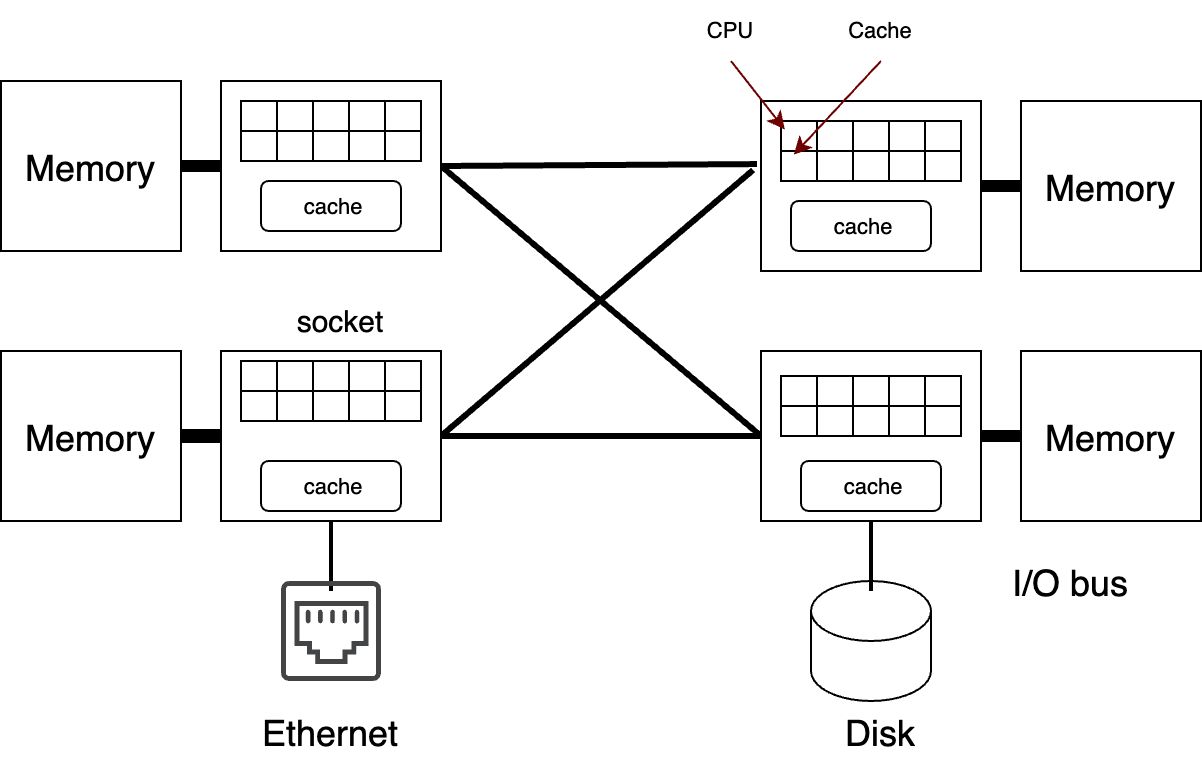
Fig. 10.11 Todays Multiprocessors#
In today’s systems a shared runqueue results in terrible performance. First, if you have hundreds of cores, the run queue itself becomes a bottleneck since only one CPU at a time can add or remove tasks from the queue. Second, with today’s large caches, you often want to run a task on the same CPU it ran on recently to reduce cache misses. Third, modern systems are NUMA, or Non Unform Memory Access (NUMA), and you want to run a task on a CPU near the memory allocated to it.
Most systems have a seperate run queue per CPU, and use some algorithm to shift tasks from one CPU to another if the imbalance between the CPUs becomes too large. The simplest algorithm, called take, has any CPU that becomes idle look at the load on the other CPUs to try to steal work. You can see here the current code in Linux for the load_balancer that is called whenever a runqueue is empty and periodically to re-balance work across the runqueus.
10.4.2. Scheduling in Linux#
Given the enormous number of platforms Linux runs on, that covers everything from Batch scheduling HPC systems, to desktops, to embedded real time, the scheduling system has had to become incredibly adaptable. You can find out a huge amount about it from the man page:
Several snippets we would like to draw your attention to that relate strongly to the materials we have presented:
Processes scheduled under one of the real-time policies (SCHED_FIFO, SCHED_RR) have a sched_priority value in the range 1 (low) to 99 (high). (As the numbers imply, real-time threads always have higher priority than normal threads.) Conceptually, the scheduler maintains a list of runnable threads for each possible sched_priority value. In order to determine which thread runs next, the scheduler looks for the non empty list with the highest static priority and selects the thread at the head of this list.
All scheduling is preemptive: if a thread with a higher static priority becomes ready to run, the currently running thread will be preempted and returned to the wait list for its static priority level. The scheduling policy determines the ordering only within the list of runnable threads with equal static priority.
Linux supports a number of policies that might sound familiar that can be specified on a per-task basis:
SCHED_FIFO: tasks will immediately preempt any currently running SCHED_OTHER, SCHED_BATCH, or SCHED_IDLE thread. SCHED_FIFO is a simple scheduling algorithm without time slicing.
SCHED_RR: Round-robin scheduling - incorporates a quantum.
SCHED_DEADLINE: Sporadic task model deadline scheduling; period real time tasks, where user specifies the period, expected Runtime, and Deadline
SCHED_OTHER (or SCHED_NORMAL): Default Linux time-sharing scheduling the standard Linux time-sharing scheduler that is intended for all threads that do not require the special real-time mechanisms. One can use nice to specify, depending on the schedular, the relative importance of different tasks.
SCHED_BATCH: This policy will cause the scheduler to always assume that the thread is CPU-intensive.
SCHED_IDLE: This policy is used for running jobs at extremely low priority.
Only privaledged tasks can set static prioritis; appropriate for single user systems where someone can specify the absolute priority of different work. The RLIMIT_RTTIME resource limit to set a ceiling on the CPU time that a real-time process may consume in order to gaurantee that real time tasks cannot cause starvation.
Prior to kernel version 2.6.23, the normal scheduler for Linux combined priority queues with a heuristic that altered a process’s priority based on the amount of a time slice it used. CPU-bound processes would consume their entire slice and would drop in priority. Conversely, I/O-bound processes would often block before consuming an entire time slice and so their priority would be increased. This was meant to allow for interactive processes to stay in the high priority queues and batch processing jobs (really anything that was CPU-bound) to drop. This scheduler had a number of heuristics that were used in decision making that were also exposed as tunable parameters, but the biggest feature it boasted was that it had O(1) run time. In other words, the time to select the next process was constant, regardless of how many runnable processes there were in the system. This is basically a varient of the MLF we have discussed.
The completely fair scheduler was a from-scratch redesign of the Linux scheduler; it did away with priority queues and with all1 heuristics and tunables found in the O(1) scheduler. CFS introduced keeping a counter for the amount of runtime each task has received and this counter is used to decide on the next task to run. Instead of priority queues CFS places all tasks in a red-black tree sorted on their accumulated runtime with tasks on the left having less accumulated run time than tasks on the right. When the system needs a new task to run, the left most task is selected. This change allows CFS to completely avoid the starvation of CPU bound tasks that could occur with the previous scheduler.
- 1
CFS still has a single tunable than can be exposed, but the kernel must be configured with
SCHED_DEBUGselected.