File System Abstraction
Contents
20. File System Abstraction#
From a user perspective, file systems support:
a name space, the set of names that identify objects;
objects such as the files themselves as well as directories and other supporting objects;
operations on these objects.
We first describe how naming works in a Unix file system, then some of the core objects and how they are identified, and then the operations a process can perform on those objects.
20.1. Naming#
Most file systems today support a tree-structured namespace1, as shown in Fig. 20.1. This tree is constructed via the use of directories, or objects in the namespace which map strings to further file system objects. A full filename thus specifies a path from the root, through the tree, to the object (a file or directory) itself. (Hence the use of the term “path” to mean “filename” in Unix documentation.)
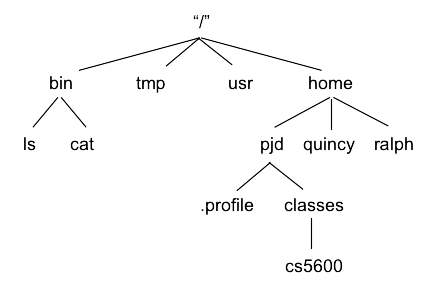
Fig. 20.1 Logical view: hierarchical file system name space#
Each process has an associated current directory, which may be changed via the chdir system call. File names beginning with ‘/’ are termed absolute names, and are interpreted relative to the root of the naming tree, while relative names are
interpreted beginning at the current directory. Thus in the file system in
Fig. 20.1, if the current directory were /home,
the the paths pjd/.profile and /home/pjd/.profile refer to the same
file, and ../bin/cat and /bin/cat refer to the same file.
Each directory also contains two special files . and .., where d/.. identifies the parent directory of d, and d/. identifies d
itself.
A typical system may provide access to
several file systems at once, e.g., a local disk and an external USB
drive or network volume. In order to unambiguously specify a file we
thus need to both identify the file within possibly nested directories
in a single file system, as well as identifying the file system itself.
Unix enables a file system to be mounted onto a directory in
another file system, giving a single uniform namespace. For example, on the systems you are using, there is an ext4 file system mounted in the root file system at /opt/app-root/src, which you can see if you use the mount command to list all the file systems mounted on this computer.
The actual implementation of mounting in Linux and other Unix-like systems is implemented via a mount table, a small table in the kernel mapping directories to directories on other file systems. As the kernel translates a pathname it checks each directory in this table; if found, it substitutes the mapped file system and directory before searching for an entry. Thus before searching “/opt/app-root/src” on for the entry “foo”, the kernel will substitute the top-level directory on the mounted ext4 files system then search for “foo”.
For a more thorough explanation of path translation in Linux and other
Unix systems see the path_resolution(7) man page, i.e. type man path_resolution.
20.2. Objects#
Once you use a pathname to find an object in the file system, you need to find out what kind of an object you have found. Each file is identified in the file system by a unique inode number that references an inode data structure that maintains all kinds of information, or meta-data about the file (try man inode for more information). While the inode itself is internal to the file system, and contains additional information, generic information can be obtained for any file as described below. One of the fields in an inode identifies the type of object that the inode refers to. The types of objects that can be referenced by inode are shown in Table 20.1.
Name |
Value |
Purpose |
|---|---|---|
regular file |
S_IFREG |
A regular file normally used to store data |
directory |
S_IFDIR |
A special file used to contain files or other directories |
symbolic link |
S_IFLNK |
A kind of “file” that is essentially a pointer to another file name |
block device |
S_IFBLK |
A device that like a disk that is accessed by reading and writing blocks |
character device |
S_IFCHR |
A charter device like a |
FIFO |
S_IFIFO |
A pipe |
socket |
S_IFSOCK |
A socket used for networking |
The last four are special files that you can connect into a file system. The first three are core objects for all file systems.
20.2.1. Files#
In keeping with the idea that everything is a file, Unix made all files just a sequence of 8-bit bytes23. Any structure to the file (such as a JPEG image, an executable program, or a database) is the responsibility of applications which read and write the file. The file format is commonly indicated by a file extension like .jpg or .xml, but this is just a convention followed by applications and users. You can do things like rename file.pdf to file.jpg, which will confuse some applications and users, but it will have no effect on the file contents.
Data in a byte-sequence file is identified by the combination of the
file and its offset (in bytes) within the file. Unlike in-memory objects
in an application, where a reference (pointer) to a component of an
object may be passed around independently, a portion of a file cannot be
named without identifying the file it is contained in. Data in a file
can be created by a write which appends more data to the end of a
shorter file, and modified by over-writing in the middle of a file.
However, it can’t be “moved” from one offset to another: if you use a
text editor to add or delete text in the middle of a file, the editor
must re-write the entire file (or at least from the modified part to the
end).
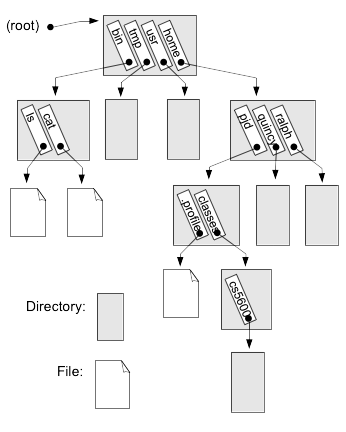
Fig. 20.2 Implementation view: hierarchical file system name space. Gray blocks are directories that contain entries with strings and corresponding inode numbers that identify the files.#
20.2.2. Directory#
As shown in Fig. 20.2, a directory contains entries with strings that identify objects contained in the directory, and for each the inode numbers that can then be used to find out more information about the corresponding object. The same inode can be referenced by multiple directories, with potentially different names. Each directory entry that maps a name to an inode number is called a hard link to the inode, and another field in the inode structure records the number of hard links to that inode. For example, the entry named .. in any directory is a hard link to the parent directory. To illustrate this point, let’s create a directory named foo in the /tmp directory and see how the link count for foo changes when we create a subdirectory bar inside foo.
As we can see, after creating a directory /tmp/foo the reference count (second entry in the output above) for the . in foo is 2 before we create a subdirectory bar in it, and 3 after. The initial two links come from the parent directory’s entry named foo, and the . entry in foo itself. After the creation of bar, there is a third link to the inode for foo due to the .. entry in bar, which refers to its parent directory.
The link count in an inode ensures that the object the inode refers to (file or directory) will not be deleted as long as there is at least one hard link to the inode. When you issue a delete command for a filename (e.g., ‘rm somefile’), the file system removes the entry for the filename from a directory and decrements the link count on the inode that entry referred to. Only when the last hard link is removed will the file object really be freed.
20.2.3. Symbolic links#
The third file system object is a symbolic link. This holds a text string which is interpreted as a “pointer” to another location in the file system. When the kernel is searching for a file and encounters a symbolic link, it substitutes this text into the current portion of the path, and continues the translation process.
This can be very useful
directory: /usr/program-1.0.1 file: /usr/program-1.0.1/file.txt sym link: /usr/program-current -> "program-1.0.1"
and if the OS is looking up the file /usr/program-current/file.txt, it
will:
look up
usrin the root directory, finding a pointer to the/usrdirectorylook up
program-currentin/usr, finding the link with contentsprogram-1.0.1look up
program-1.0.1and use this result instead of the result from looking upprogram-current, getting a pointer to the/usr/program-1.0.1directory.look up
file.txtin this directory, and find it.
Note that unlike hard links, a symbolic link does not increase the link count in the inode that it refers to. As a result, a symbolic link may be “broken”—i.e., if the file it points to does not exist. This can happen if the link was created in error, or the file or directory it points to is deleted later. In that case path translation will fail with an error:
Finally, to prevent loops there is a limit on how many levels of symbolic link may be traversed in a single path translation:
20.3. File System Operations:#
There are several common types of file operations supported by Linux (and with slight differences, Windows). They can be classified into three main categories: open/close, read/write, and naming and directories.
20.3.1. Open/close#
In order to access a file in Linux (or most operating systems) you first need to open the file, passing the file name and other parameters and receiving a handle (called a file descriptor in Unix) which may be used for further operations. The corresponding system calls are:
int desc = open(name, O_READ): Verify that filenameexists and may be read, and then return a descriptor which may be used to refer to that file when reading it.int desc = open(name, O_WRITE | flags, mode): Verify permissions and opennamefor writing, creating it (or erasing existing contents) if necessary as specified inflags. Returns a descriptor which may be used for writing to that file.close(desc): stop using this descriptor, and free any resources allocated for it.
Note that application programs rarely use the system calls themselves to access files, but instead use higher-level frameworks, ranging from Unix Standard I/O to high-level application frameworks.
20.3.1.1. Read/Write operations#
To get a file with data in it, you need to write it; to use that data you need to read it. To enable files to be accessed as a stream just like from a terminal or pipe, UNIX uses the concept of a current position
associated with a file descriptor. When you read 100 bytes (i.e. bytes 0
to 99) from a file, this pointer advances by 100 bytes, so that the next
read will start at byte 100, and similarly for write. When a file is
opened for reading the pointer starts at 0; when open for writing the
application writer can choose to start at the beginning (default) and
overwrite old data, or start at the end (O_APPEND flag) to append new
data to the file.
The read and write routines are the same ones we described before, but, for ease of reference, they are:
n = read(desc, buffer, max): Readmaxbytes (or fewer if the end of the file is reached) intobuffer, starting at the current position, and returning the actual number of bytesnread; the current position is then incremented byn.n = write(desc, buffer, len): Writelenbytes frombufferinto the file, starting at the current position, and incrementing the current position bylen.lseek(desc, offset, flag): Set an open file’s current position to that specified byoffsetandflag, which specifies whetheroffsetis relative to the beginning, end, or current position in the file.
Note that in the basic Unix interface (unlike e.g. Windows) there is no
way to specify a particular location in a file to read or write
from4. Programs like databases (e.g. SQLite, MySQL) which need to
write to and read from arbitrary file locations must instead move the
current position by using lseek before a read or write. However, most
programs either read or write a file from the beginning to the end
(especially when written for an OS that makes it easier to do things
that way), and thus don’t really need to perform seeks. Because most
Unix programs use simple “stream” input and output, these may be
re-directed so that the same program can—without any special
programming—read from or write to a terminal, a network connection, a
file, or a pipe from or to another program.
20.3.2. Naming and Directories#
In Unix there is a difference between a name (a directory entry) and the object (file or directory) that the name points to. The naming and directories operations are:
rename(path1, path2)- Rename an object (i.e., a file or directory) by either changing the name in its directory entry (if the destination is in the same directory) or creating a new entry and deleting the old one (if moving into a new directory).link(path1, path2): Add a hard link to a file5.unlink(path): Decrement the reference count to a file, if it goes to zero, delete the file6.desc = opendir(path),readdir(desc, dirent*), dirent=(name,type,length): This interface allows a program to enumerate names in a directory, and determine their type (i.e., file, directory, symbolic link, or special-purpose file).stat(file, statbuf),fstat(desc, statbuf): returns information about the file such as size, owner, permissions, modification time, etc. These are attributes of the file itself, residing in the inode and returned in the following structure.
struct stat {
dev_t st_dev; /* ID of device containing file */
ino_t st_ino; /* Inode number */
mode_t st_mode; /* File type and mode */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device ID (if special file) */
off_t st_size; /* Total size, in bytes */
blksize_t st_blksize; /* Block size for filesystem I/O */
blkcnt_t st_blocks; /* Number of 512B blocks allocated */
struct timespec st_atim; /* Time of last access */
struct timespec st_mtim; /* Time of last modification */
struct timespec st_ctim; /* Time of last status change */
};
mkdir(path),rmdir(path): directory operations: create a new, empty directory, or delete an empty directory.
20.4. Some examples#
Consider the following program in Listing 20.1, which copies one file to another. After opening the input file (line 26) we stat the input file to get the permissions (i.e., the mode), create a file with that mode (line 37), and then go into a loop reading data from the input file into a buffer, and then writing the buffer to the output file.
1// simple program to copy a file
2
3#include <sys/types.h>
4#include <fcntl.h>
5#include <stdlib.h>
6#include <unistd.h>
7#include <stdio.h>
8#include <assert.h>
9#include <sys/stat.h>
10
11#define BUF_SIZE 4096
12// user has read and write permission
13
14int main(int argc, char *argv[])
15{
16 int in_fd, out_fd, rd_count, wt_count, rc;
17 mode_t md;
18 struct stat statbuf;
19 char buffer[BUF_SIZE];
20
21 if (argc != 3) {
22 perror("Can't open input file\n");
23 exit(1);
24 }
25
26 in_fd = open(argv[1], O_RDONLY);
27 if (in_fd < 0) {
28 perror("Can't creat output file\n");
29 exit(1);
30 }
31 if ((rc = fstat(in_fd, &statbuf)) <0) {
32 perror("fstat failed\n");
33 exit(1);
34 }
35 md = statbuf.st_mode & (S_IRWXU|S_IRWXG|S_IRWXO);
36
37 out_fd = creat(argv[2], md);
38 if (out_fd < 0) {
39 perror("Can't creat output file\n");
40 exit(1);
41 }
42
43 while(1) {
44 rd_count = read(in_fd, buffer, BUF_SIZE);
45 if (rd_count==0) { // done
46 exit(0);
47 }
48 assert(rd_count > 0);
49
50
51 wt_count = write(out_fd, buffer, rd_count);
52 assert(wt_count == rd_count);
53 }
54 close(in_fd);
55 close(out_fd);
56}
To prove these are the same, let’s first use the diff program to compare them:
We can see that there is no difference between the files, since diff produces no output. But just to be sure, let’s append a string to the end of the copy (i.e., echo “Hello class” >> rm2) and use the diff program to compare them again.
And here we see that the only difference is the line we just appended to the copy of the original README.md file.
- 1
Very early file systems sometimes had a single flat directory per user, or like MS-DOS 1.0, a single directory per floppy disk
- 2
it is probably not a coincidence that Unix arrived at the same time as computers which dealt only with multiples of 8-bit bytes (e.g. 16 and 32-bit words), replacing older systems which frequently used odd word sizes such as 36 bits. (Note that a machine with 36-bit instructions already needs two incompatible types of files, one for text and one for executable code.)
- 3
This is the case for almost all operating systems today, but… of course there are exceptions. Apple OSX uses resource forks to store information associated with a file (HFS and HFS+ file systems only), Windows NTFS provides for multiple data streams in single file, although they were never put to use, and several file systems support file attributes, which are small tags associated with a file.
- 4
On Linux the
preadandpwritesystem calls allow specifying an offset for the read or write; other UNIX-derived operating systems have their own extensions for this purpose.- 5
A hard link is an additional directory entry pointing to the same file, giving the file two (or more) names. Hard links are peculiar to Unix, and in modern systems have mostly been replaced with symbolic links (covered above); however Apple’s Time Machine makes very good use of them: multiple backups can point to the same single copy of an un-modified file using hard links.
- 6
Even when the reference count goes to zero, the file might not be removed yet - on Unix, if you delete an open file it won’t actually be removed until all open file handles are closed.. In general, deleting open files is a problem: while Unix solves the problem by deferring the actual delete, Windows solves it by protecting open files so that they cannot be deleted.