More on Disks
Contents
30. More on Disks#
Earlier we introduced Disk hardware in sufficient detail to enable us to introduce file systems. In this section we go deeper discussing how disks are scheduled, cover RAID storage systems, a bit on SSDs, etc…
30.1. Disk scheduling#
A number of strategies are used to avoid the full penalties of seek and rotational delay in disks. One of these strategies is that of optimizing the order in which requests are performed—for instance reading sectors 10 and 11 on a single track, in that order, would require a seek, followed by a rotational delay until sector 10 was available, and then two sectors of transfer time. However reading 11 first would require the same seek and about the same rotational delay (waiting until sector 11 was under the head), followed by a full rotation to get from section 12 all the way back to sector 10.
Changing the order in which disk reads and writes are performed in order to minimize disk rotations is known as disk scheduling, and relies on the fact that multitasking operating systems frequently generate multiple disk requests in parallel, which do not have to be completed in strict order. Although a single process may wait for a read or write to complete before continuing, when multiple processes are running they can each issue requests and go to sleep, and then be woken in the order that requests complete.
30.1.1. Primary Disk Scheduling Algorithms#
The primary algorithms used for disk scheduling are:
first-come first-served (FCFS): in other words no scheduling, with requests handled in the order that they are received.
Shortest seek time first (SSTF): this is the throughput-optimal strategy; however it is prone to starvation, as a stream of requests to nearby sections of the disk can prevent another request from being serviced for a long time.
SCAN: this (and variants) are what is termed the elevator algorithm — pending requests are served from the inside to the outside of the disk, then from the outside back in, etc., much like an elevator goes from the first floor to the highest requested one before going back down again. It is nearly as efficient as SSTF, while avoiding starvation. (With SSTF one process can keep sending requests which will require less seek time than another waiting request, “starving” the waiting one.)
More sophisticated disk head scheduling algorithms exist, and could no doubt be found by a scan of the patent literature; however they are mostly of interest to hard drive designers.
30.1.2. Implementing Disk Scheduling#
Disk scheduling can be implemented in two ways — in the operating system, or in the device itself. OS-level scheduling is performed by keeping a queue of requests which can be re-ordered before they are sent to the disk. On-disk scheduling requires the ability to send multiple commands to the disk before the first one completes, so that the disk is given a choice of which to complete first. This is supported as Command Queuing in SCSI, and in SATA as Native Command Queuing (NCQ).
Note that OS-level I/O scheduling is of limited use today for improving overall disk performance, as the OS has little or no visibility into the internal geometry of a drive. (OS scheduling is still used to merge adjacent requests into larger ones and to allocate performance fairly to different processes, however.)
30.2. On-Disk Cache#
In addition to scheduling, the other strategy used to improve disk performance is caching, which takes two forms—read caching (also called track buffering) and write buffering. Disk drives typically have a small amount of RAM used for caching data [^3]. Although this is very small in comparison the the amount of RAM typically dedicated to caching on the host, if used properly it can make a significant difference in performance.
At read time, after seeking to a track it is common practice for the disk to store the entire track in the on-disk cache, in case the host requests this data in the near future. Consider, for example, the case when the host requests sector 10 on a track, then almost (but not quite) immediately requests sector 11. Without the track buffer it would have missed the chance to read 11, and would have to wait an entire revolution for it to come back around; with the track buffer, small sequential requests such as this can be handled efficiently.
Write buffering is a different matter entirely, and refers to a feature where a disk drive may acknowledge a write request while the data is still in RAM, before it has been written to disk. This can risk loss of data, as there is a period of time during which the application thinks that data has been safely written, while it would in fact be lost if power failed.
Although in theory most or all of the performance benefit of write buffering could be achieved in a safer fashion via proper use of command queuing, this feature was not available (or poorly implemented) in consumer drives until recently; as a result write buffering is enabled in SATA drives by default. Although write buffering can be disabled on a per-drive basis, modern file systems typically issue commands[^4] to flush the cache when necessary to ensure file system data is not lost.
30.3. SATA and SCSI#
Almost all disk drives today use one of two interfaces: SATA (or its precursor, IDE) or SCSI. The SATA and IDE interfaces are derived from an ancient disk controller for the PC, the ST-506, introduced in about 1980. This controller was similar to—but even cruder than—the disk interface in our fictional computer, with registers for the command to execute (read/write/other) and address (cylinder/head/sector), and a single register which the CPU read from or wrote to repeatedly to transfer data. What is called the ATA (AT bus-attached) or IDE (integrated drive electronics) disk was created by putting this controller on the drive itself, and using an extender cable to connect it back to the bus, so that the same software could still access the control registers. Over the years many extensions were made, including DMA support, logical block addressing, and a high-speed serial connection instead of a multi-wire cable; however the protocol is still based on the idea of the CPU writing to and reading from a set of remote, disk-resident registers.
In contrast, SCSI was developed around 1980 as a high-level, device-independent protocol with the following features:
Packet-based. The initiator (i.e. host) sends a command packet (e.g. READ or WRITE) over the bus to the target; DATA packets are then sent in the appropriate direction followed by a status indication. SCSI specifies these packets over the bus; how the CPU interacts with the disk controller to generate them is up to the maker of the disk controller. (often called an HBA, or host bus adapter)
Logical block addressing. SCSI does not support C/H/S addressing — instead the disk sectors are numbered starting from 0, and the disk is responsible for translating this logical block address (LBA) into a location on a particular platter. In recent years logical addressing has been adopted by IDE and SATA, as well.
30.4. SCSI over everything#
SCSI (like e.g. TCP/IP) is defined in a way that allows it to be carried across many different transport layers. Thus today it is found in:
USB drives. The USB storage protocol transports SCSI command and data packets.
CD and DVD drives. The first CD-ROM and CD-R drives were SCSI drives, and when IDE CDROM drives were introduced, rather than invent a new set of commands for CD-specific functions (e.g. eject) the drive makers defined a way to tunnel existing SCSI commands over IDE/ATA (and now SATA).
Firewire, as used in some Apple systems.
Fibre Channel, used in enterprise Storage Area Networks.
iSCSI, which carries SCSI over TCP/IP, typically over Ethernet
and no doubt several other protocols as well. By using SCSI instead of defining another block protocol, the device makers gained SCSI features like the following:
Standard commands (“Mode pages”) for discovering drive properties and parameters.
Command queuing, allowing multiple requests to be processed by the drive at once. (also offered by SATA, but not earlier IDE drives)
Tagged command queuing, which allows a host to place constraints on the re-ordering of outstanding requests.
30.5. RAID and other remapping technologies#
There is no need for the device on the other end of the SCSI (or SATA) bus to actually be a disk drive. (You can do this with C/H/S addressing, as well, but it requires creating a fake drive geometry, and then hoping that the operating system won’t assume that it’s the real geometry when it schedules I/O requests) Instead the device on the other end of the wire can be an array of disk drives, a solid-state drive, or any other device which stores and retrieves blocks of data in response to write and read commands. Such disk-like devices are found in many of today’s computer systems, both on the desktop and especially in enterprise and data center systems, and include:
Partitions and logical volume management, for flexible division of disk space
Disk arrays, especially RAID (redundant arrays of inexpensive disks), for performance and reliability
Solid-state drives, which use flash memory instead of magnetic disks
Storage-area networks (SANs)
De-duplication, to compress multiple copies of the same data
Almost all of these systems look exactly like a disk to the operating system. Their function, however, is typically (at least in the case of disk arrays) an attempt to overcome one or more deficiencies of disk drives, which include:
Performance: Disk transfer speed is determined by (a) how small bits can be made, and (b) how fast the disk can spin under the head. Rotational latency is determined by (b again) how fast the disk spins. Seek time is determined by (c) how fast the head assembly can move and settle to a final position. For enough money, you can make (b) and (c) about twice as fast as in a desktop drive, although you may need to make the tracks wider, resulting in a lower-capacity drive. To go any faster requires using more disks, or a different technology, like SSDs.
Reliability: Although disks are surprisingly reliable, they fail from time to time. If your data is worth a lot (like the records from the Bank of Lost Funds), you will be willing to pay for a system which doesn’t lose data, even if one (or more) of the disks fails.
Size: The maximum disk size is determined by the available technology at any time—if they could build them bigger for an affordable price, they would. If you want to store more data, you need to either wait until they can build larger disks, or use more than one. Conversely, in some cases (like dual-booting) a single disk may be more than big enough, but you may need to split it into multiple logical parts.
We discuss RAID systems and SSDs.
30.5.1. Striping — RAID0#
If the file was instead split into small chunks, and each chunk placed on a different disk than the chunk before it, it would be possible to read and write to all disks in parallel. This is called striping, as the data is split into stripes which are spread across the set of drives.
In Fig. 30.1 we see individual strips, or chunks of data, layed out in horizontal rows (called stripes) across three disks. In the figure, when writing strips 0 through 5, strips 0, 1, and 2 would be written first at the same time to the three different disks, followed by writes to strips 3, 4, and 5. Thus, writing six strips would take the same amount of time it takes to write two strips to a single disk.
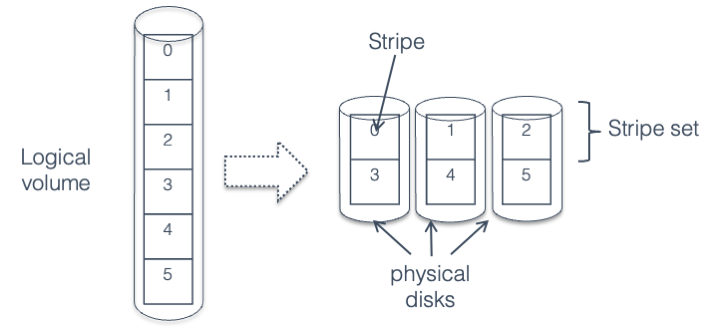
Fig. 30.1 Striping across three disks#
How big is a strip? It depends, as this value is typically
configurable—the RAID algorithms work with any strip size, although
for convenience everyone uses a power of 2. If it’s too small, the large
number of I/Os may result in overhead for the host (software RAID) or
for the RAID adapter; if it’s too large, then large I/Os will read or
write from individual disks one at a time, rather than in parallel.
Typical values are 16 KB to 512 KB. (the last one is kind of large, but
it’s the default built into the mdadm utility for creating software
RAID volumes on Linux. And the mdadm man page calls them “chunks”
instead of “strips”, which seems like a much more reasonable name.)
Striping data across multiple drives requires translating an address within the striped volume to an address on one of the physical disks making up the volume, using these steps:
Find the stripe set that the address is located in - this will give the stripe number within an individual disk.
Calculate the stripe number within that stripe set, which tells you the physical disk the stripe is located on.
Calculate the address offset within the stripe.
Note that each disk must be of the same size for striping to work. (Well, if any disks are bigger than the smallest one, that extra space will be wasted.)
30.5.2. Mirroring — RAID1#

Fig. 30.2 Failure of one disk in
a mirrored volue.#
Disks fail, and if you don’t have a copy of the data on that disk, it’s lost. A lot of effort has been spent on creating multi-disk systems which are more reliable than single-disk ones, by adding redundancy—i.e. additional copies of data so that even if one disk fails completely there is still a copy of each piece of your data stored safely somewhere. (Note that striping is actually a step in the wrong direction - if any one of the disks in a striped volume fail, which is more likely than failure of a single disk, then you will almost certainly lose all the data in that volume.)
The simplest redundant configuration is mirroring, where two identical (“mirror image”) copies of the entire volume are kept on two identical disks. In Fig. 30.2 we see a mirrored volume comprising two physical disks; writes are sent to both disks, and reads may be sent to either one. If one disk fails, reads (and writes) will go to the remaining disk, and data is not lost. After the failed disk is replaced, the mirrored volume must be rebuilt (sometimes termed “re-silvering”) by copying its contents from the other drive. If you wait too long to replace the failed drive, you risk having the second drive crash, losing your data.
Address translation in a mirrored volume is trivial: address A in the logical volume corresponds to the same address A on each of the physical disks. As with striping, both disks must be of the same size. (or any extra sectors in the larger drive must be ignored.)
30.5.3. RAID 4#
Although mirroring are good for constructing highly reliable storage systems, sometimes you don’t want reliability bad enough to be willing to devote half of your disk space to redundant copies of data. This is where RAID 4 (and the related RAID 5) come in.
For the 8-disk RAID 1+0 volume described previously to fail, somewhere between 2 and 5 disks would have to fail (3.66 on average). If you plan on replacing disks as soon as they fail, this may be more reliability than you need or are willing to pay for. RAID 4 provides a high degree of reliability with much less overhead than mirroring.

RAID 4 takes N drives and adds a single parity drive, creating an array that can tolerate the failure of any single disk without loss of data. It does this by using the parity function (also known as exclusive-OR, or addition modulo 2), which has the truth table seen in the figure to the right. As you can see in the equation, given the parity calculated over a set of bits, if one bit is lost, it can be re-created given the other bits and the parity. In the case of a disk drive, instead of computing parity over N bits, you compute it over N disk blocks, as shown here where the parity of two blocks is computed:
001010011101010010001 ... 001101010101 +
011010100111010100100 ... 011000101010
= 010000111010000110101 ... 010101111111

Fig. 30.3 RAID 4 organization#

Fig. 30.4 RAID 4 organization (disk view)#
RAID 4 is organized almost exactly like a striped (RAID 0) volume, except for the parity drive. We can see this in Fig. 30.3 — each data block is located in the same place as in the striped volume, and then the corresponding parity block is located on a separate disk.
30.5.4. RAID 5#
Small writes to RAID 4 require four operations: one read each for the old data and parity, and one write for each of the new data and parity. Two of these four operations go to the parity drive, no matter what LBA is being written, creating a bottleneck. If one drive can handle 200 random operations per second, the entire array will be limited to a total throughput of 100 random small writes per second, no matter how many disks are in the array.
By distributing the parity across drives in RAID 5, the parity bottleneck is eliminated. It still takes four operations to perform a single small write, but those operations are distributed evenly across all the drives. (Because of the distribution algorithm, it’s technically possible for all the writes to go to the same drive; however it’s highly unlikely.) In the five-drive case shown here, if a disk can complete 200 operations a second, the RAID 4 array would be limited to 100 small writes per second, while the RAID 5 array could perform 250. (5 disks = 1000 requests/second, and 4 requests per small write)

Fig. 30.5 RAID 5#
30.5.5. RAID 6 - more reliability#
RAID level 1, and levels 4 and 5 are designed to protect against the total failure of any single disk, assuming that the remaining disks operate perfectly. However, there is another failure mode known as a latent sector error, in which the disk continues to operate but one or more sectors are corrupted and cannot be read back. As disks become larger these errors become more problematic: for instance, one vendor specifies their current desktop drives to have no more than 1 unrecoverable read error per \(10^{14}\) bits of data read, or 12.5 TB. In other words, there might be in the worst case a 1 in 4 chance of an unrecoverable read error while reading the entire contents of a 3TB disk. (Luckily, actual error rates are typically much lower, but not low enough.)
If a disk in a RAID 5 array fails and is replaced, the “rebuild” process requires reading the entire contents of each remaining disk in order to reconstruct the contents of the failed disk. If any block in the remaining drives is unreadable, data will be lost. (Worse yet, some RAID adapters and software will abandon the whole rebuild, causing the entire volume to be lost.)
RAID 6 refers to a number of RAID mechanisms which add additional redundancy, using a second parity drive with a more complex error-correcting code. If a read failure occurs during a RAID rebuild, this additional protection may be used to recover the contents of the lost block, preventing data loss. Details of RAID 6 implementation will not be covered in this class, due to the complexity of the codes used.
30.6. Solid State Drives#
Solid-state drives (SSDs) store data on semiconductor-based flash memory instead of magnetic disk; however by using the same block-based interface (e.g. SATA) to connect to the host they are able to directly replace disk drives.
SSDs rely on flash memory, which stores data electrically: a high programming voltage is used to inject a charge onto a circuit element (a floating gate—ask your EE friends if you want an explanation) that is isolated by insulating layers, and the presence or absence of such a stored charge can be detected in order to read the contents of the cell. Flash memory has several advantages over magnetic disk, including:
Random access performance: since flash memory is addressed electrically, instead of mechanically, random access can be very fast.
Throughput: by using many flash chips in parallel, a consumer SSD (in
can read speeds of 1-2 GB/s, while the fastest disks are limited to a bit more than 200MB/s.
Flash is organized in pages of 4KB to 16KB, which must be read or written as a unit. These pages may be written only once before they are erased in blocks of 128 to 256 pages, making it impossible to directly modify a single page. Instead, the same copy-on-write algorithm used in LVM snapshots is used internally in an SSD: a new write is written to a page in one of a small number of spare blocks, and a map is updated to point to the new location; the old page is now invalid and is not needed. When not enough spare blocks are left, a garbage collection process finds a block with many invalid pages, copies any remaining valid pages to another spare block, and erases the block.
When data is written sequentially, this process will be efficient, as the garbage collector will almost always find an entirely invalid block which can be erased without any copying. For very random workloads, especially on cheap drives with few spare blocks and less sophisticated garbage collection, this process can involve huge amounts of copying (called write amplification) and run very slowly.
SSD Wear-out: Flash can only be written and erased a certain number of times before it begins to degrade and will not hold data reliably: most flash today is rated for 3000 write/erase operations before it becomes unreliable. The internal SSD algorithms distribute writes evenly to all blocks in the device, so in theory you can safely write 3000 times the capacity of a current SSD, or the entire drive capacity every day for 8 years. (Note that 3000 refers to internal writes; random writes with high write amplification will wear out an SSD more than the same volume of sequential writes.)
For a laptop or desktop this would be an impossibly high workload, especially since they are typically used only half the hours in a day or less. For some server applications, however, this is a valid concern. Special-purpose SSDs are available (using what is called Single-Level Cell, or SLC, flash) which are much more expensive but are rated for as many as 100,000 write/erase cycles. (This capacity is the equivalent of overwriting an entire drive every 30 minutes for 5 years. For a 128GB drive, this would require continuously writing at over 70MB/s, 24 hours a day.)