Kernel implementation
Contents
Warning
This portion of the book is under construction, not ready to be read
22.7. Kernel implementation#
When applications access files they identify them by file and directory names, or by file descriptors (handles), and reads and writes may be performed in arbitrary lengths and alignments. These requests need to be translated into operations on the on-disk file system, where data is identified by its block number and all reads and writes must be in units of disk blocks.
The primary parts of this task are:
Path translation - given a list of path components (e.g. “usr”, “local”, “bin”, “program”) perform the directory lookups necessary to find the file or directory named by that list.
Read and write - translate operations on arbitrary offsets within a file to reads, writes, and allocations of complete disk blocks.
Path translation is a straightforward tree search - starting at the root directory, search for an entry for the first path component, find the location for that file or directory, and repeat until the last component of the list has been found, or an error has occurred. (Not counting permissions, there are two possible errors here—either an entry of the path was not found, or a non-final component was found but was a file rather than a directory.)
Reading requires finding the blocks which must be read, reading them in, and copying the requested data (which may not be all the data in the blocks, if the request does not start or end on a block boundary) to the appropriate locations in the user buffer.
Writing is similar, with added complications: if a write starts in the middle of a block, that block must be read in, modified, and then written back so that existing data is not lost, and if a write extends beyond the end of the file new blocks must be allocated and added to the file.
As an example, to handle the system calls
fd = open("/home/pjd/file.txt", O_RDONLY)
read(fd, buf, 1024)
the kernel has to perform the following steps:
Split the string
/home/pjd/file.txtinto parts -home,pjd,file.txtRead the root directory inode to find the location of the root directory data block. (let’s assume it’s a small directory, with one block)
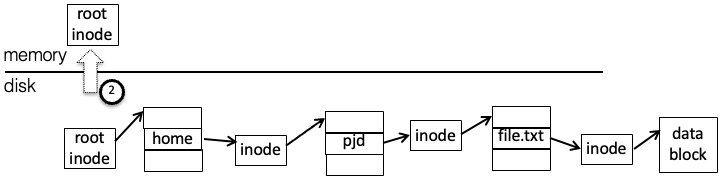
Read the root directory data block, search for
"home", and find the corresponding inode numberRead the inode for the directory
"home"to get the data block pointer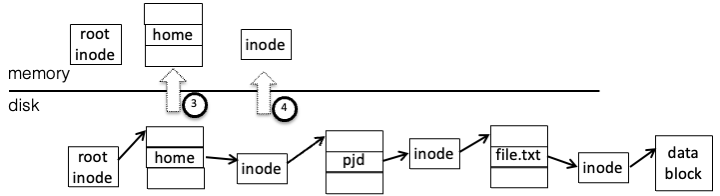
Read the
"home"directory data block, search for"pjd"to get the inode numberRead the
"pjd"directory inode, get the data block pointer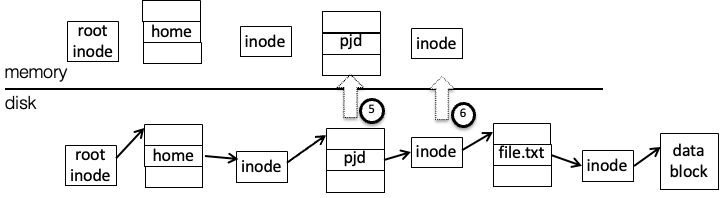
Read the
"pjd"directory block, and find the entry forfile.txtRead the
"file.txt"inode and get the first data block pointerRead the data block into the user buffer
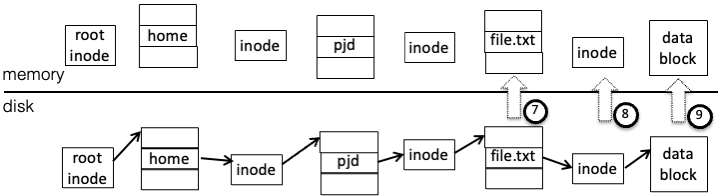
Most of this work (steps 2 through 7) is path translation, or the process of traversing the directory tree to find the file itself. In doing this, the OS must handle the following possibilities:
The next entry in the path may not exist - the user may have typed
/hme/pjd/file.txtor/home/pjd/ffile.txtAn intermediate entry in the path may be a file, rather than a directory - for instance
/home/pjd/file.txt/file.txtThe user may not have permissions to access one of the entries in the path. On the CCIS systems, for instance, if a user other than pjd tries to access
/home/pjd/classes/file.txt, the OS will notice that/home/pjd/classesis protected so that only userpjdmay access it.
22.7.1. Caching#
Disk accesses are slow, and multiple disk accesses are even slower. If every file operation required multiple disk accesses, your computer would run very slowly. Instead much of the information from the disk is cached in memory in various ways so that it can be used multiple times without going back to disk. Some of these ways are:
File descriptors: When an application opens a file the OS must translate the path to find the file’s inode; the inode number and information from that inode can then be saved in a data structure associated with that open file (a file descriptor in Unix, or file handle in Windows), and freed when the file descriptor is closed.
Translation caching: An OS will typically maintain an in-memory translation cache (the dentry cache in Linux, holding individual directory entries) which holds frequently-used translations, such as root directory entries.
The directory entry cache differs from e.g. a CPU cache in that it holds both normal entries (e.g. directory+name to inode) and negative entries, indicating that directory+name does not exist1. If no entry is found the directory is searched, and the results added to the dentry cache.
Block caching: To accelerate reads of frequently-accessed blocks, rather than directly reading from the disk the OS can maintain a block cache. Before going to disk the OS checks to see whether a copy of the disk block is already present; if so the data can be copied directly, and if not it is read from disk and inserted into the cache before being returned. When data is modified it can be written to this cache and written back later to the disk.
Among other things, this allows small reads (smaller than a disk block) and small writes to be more efficient. The first small read will cause the block to be read from disk into cache, while following reads from the same block will come from cache. Small writes will modify the same block in cache, and if a block is not flushed immediately to disk, it can be modified multiple times while only resulting in a single write.
Modern OSes like Linux use a combined buffer cache, where virtual memory pages and the file system cache come from the same pool. It’s a bit complicated, and is not covered in this class.
22.7.2. VFS#
In order to support multiple file systems such as Ext3, CD-ROMs, and others at the same time, Linux and other Unix variants use an interface called VFS, or the Virtual File System interface. (Windows uses a much different interface with the same purpose.) The core of the OS does not know how to interpret individual file systems; instead it knows how to make requests across the VFS interface. Each file system registers an interface with VFS, and the methods in this interface implement the file system by talking to e.g., a disk or a network server.
VFS objects all exist in memory; any association between these structures and data on disk is the responsibility of the file system code. The important objects and methods in this interface are:
superblock. Not to be confused with the superblock on disk, this
object corresponds to a mounted file system; in particular, the system
mount table holds pointers to superblock structures. The most important
field in the superblock object is a pointer to the root directory
inode.
inode - this corresponds to a file or directory. Its methods allow
attributes (owner, timestamp, etc.) to be modified; in addition, if the
object corresponds to a directory, other methods allow creating,
deleting, and renaming entries, as well as looking up a string to return
a directory entry.
dentry - an object corresponding to a directory entry, as described
earlier. It holds a name and a pointer to the corresponding
inode object, and no interesting methods.
file - this corresponds to an open file. When it is created there is
no associated “real” file; its open method is called with a dentry
pointing to the file to open.
To open a file the OS will start with the root directory inode (from the
superblock object) and call lookup, getting back a dentry with a
pointer to the next directory, etc. When the dentry for the file is
found, the OS will create a file object and pass the dentry to the file
object’s open method.
FUSE (File system in User Space) is a file system type in Linux which does not actually implement a file system itself, but instead forwards VFS requests to a user-space process, and then takes the responses from that process and passes them back to the kernel.
Like VFS, the FUSE interface consists of a series of methods which you must implement, and if you implement them correctly and return consistent results, the kernel (and applications running on top of it) will see a file system. Unlike VFS, FUSE includes various levels of user-friendly support; we will use it in a mode where all objects are identified by human-readable path strings, rather than dentries and inodes.
getattr- return attributes (size, owner, etc.) of a file or directory.readdir- list a directorymkdir,rmdir,create,unlink- create and remove directories and filesread,write- note that these identify the offset in the file, as the kernel (not the file system) handles file positions.rename- change a name in a directory entrytruncate- shorten a file… and others, most of which are optional.
22.7.3. Network File Systems#
The file systems discussed so far are local file systems, where data is stored on local disk and is only directly accessible from the computer attached to that disk. Network file systems are used when we want access to data from multiple machines.
The two network file systems in most common use today are Unix NFS (Network File System) and Windows SMB (also known as CIFS). Each protocol provides operations somewhat similar to those in VFS (quite similar in the case of NFS, as the original VFS was designed for it), allowing the kernel to traverse and list directories, create and delete files, and read and write arbitrary offsets within a file.
The primary differences between the NFS (up through v3 at least, v4 is more complicated) and SMB are:
State - NFS is designed to be stateless for reliability. Once you have obtained a file’s unique ID (from the directory entry) you can just read from or write to a location in it, without opening the file. Operations are idempotent, which means they can be repeated multiple times without error (e.g., writing page P to offset x can be repeated, while appending page P to the end of the file can’t). In contrast SMB is connection-oriented, and requires files and directories to be opened before they can be operated on. NFS tolerates server crashes and restarts more gracefully, but does not have some of the connection-related features in SMB such as authentication, described below.
Identity - NFS acts like a local file system, trusting the client to authenticate users and pass numeric user IDs to the server. SMB handles authentication on the server side—each connection to the server begins with a handshake that authenticates to the server with a specific username, and all operations within that connection are done as that user.
- 1
To be a bit formal about it, a CPU cache maps a dense address space, where every key has a value, while the translation cache maps a sparse address space.