Virtualizing the CPU
8. Virtualizing the CPU#
When we say “virtualizing” what we mean is actually adding a layer of indirection between the target (in this case the CPU) and the source (the process), enabling multiple processes to take turns using the same CPU; that is time multiplexing the CPU. In order to do this, we will need a way of pausing the execution of a process while another process runs and then resuming execution later without the process having to be aware of this pause, which means we need to capture all of the state that is relevant to a process in one or more data structures we can use to hold them when the process is not active. When the OS changes the active process on a CPU, we call this a context switch. To complete a context switch we need to save the CPU state for the process coming off the CPU and then load the state for the incoming process before allowing the CPU to execute the incoming process.
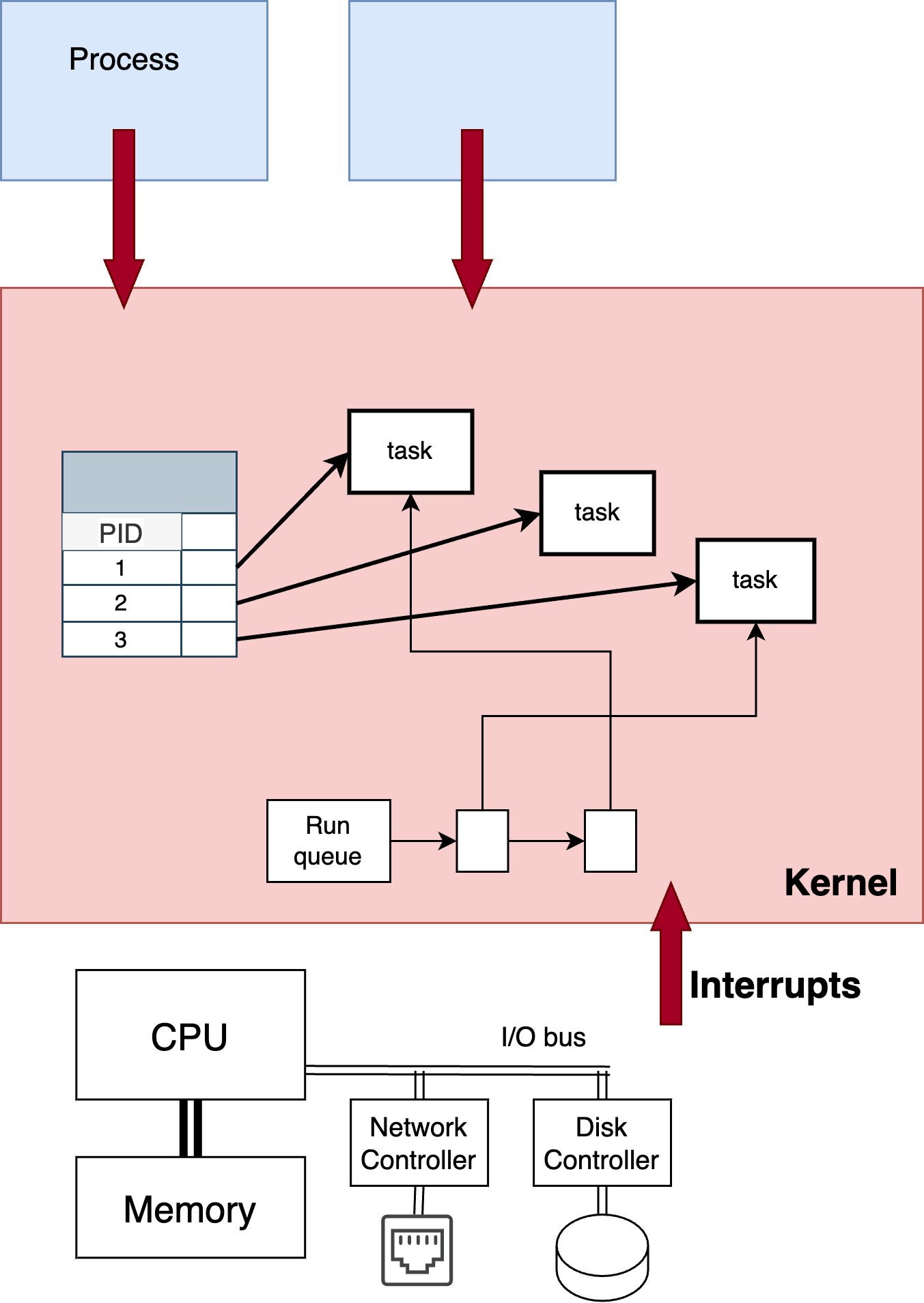
Fig. 8.1 For each process, a task structure contains information about each of the processes. All processes that are ready to run are on a queue#
We stated earlier (see Fig. 4.2) the kernel maintains a table of all processes, indexed by the process id, or pid, to keep track of all the information about each process. For reasons that will soon make sense, rather than processes, we will refer here to the abstraction that the kernel runs on the processor as a task, although feel free to think about a task as being a process for the time being. As shown in Fig. 4.2, the kernel maintains a data structures, we call here a run queue for scheduling the tasks on the CPU. On a single CPU (actually single core) system, only one task can run at a time, and the kernel is responsible for selecting the task to be run and switching between them.
For each task, the kernel maintains a pointer to the file descriptor table, the memory management data structures (i.e. the map described above) and information about execution state of the task. For example, Listing 8.1 shows a highly simplified version of the task_struct data structure used by Linux. The state field indicates if the task is currently running, is blocked for some reason, or is ready and waiting to be run. The thread structure is a place for the kernel to store all the processor registers whenever the task is not running.
Note
There is much more state in the task structure including:
Process ID, User ID, Group ID
Priority/Scheduling parameters
Accounting information
Signal management functions
Working directory To see the actual data structure, you can use the online browser for the current linux code base, and search for
task_structat this link.
1struct task_struct {
2 // the state of the task: running, blocked, runable
3 unsigned int __state;
4
5 // CPU-specific state of this task
6 struct thread_struct thread;
7
8 // a pointer to the memory management data structures
9 struct mm_struct *mm;
10
11 // Open file information
12 struct files_struct *files;
13}
Fig. 8.2 shows the three possible states for a task, with all the valid state transitions represented by arrows. A task in the Running state is one that is currently active on a CPU. Processes do many things other than just use the CPU, e.g., they read data from files, communicate with other processes, etc… For example, as I type this, the process is constantly blocked waiting for me to type characters. Some examples of blocking operations are: issuing a read from disk or from a network socket that does not have data ready, issuing a write to a pipe that has no more space to buffer data, trying to acquire certain kinds of resources that are already owned by another process or thread, etc.
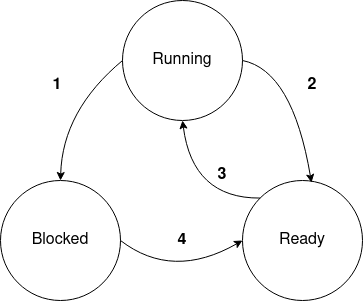
Fig. 8.2 Task states#
In these situations, the process must wait for something external to happen before it can make progress (e.g., data arrives over the network, another process reads some data out of the pipe, the requested resource is released by another process, etc.), and is unable to make use of the CPU until that event occurs. We would be wasting the limited CPU resource if we left such a process on the CPU, and there is no point considering it among the set of runnable processes that we might want to choose next either. Tasks that are waiting for something go into the Blocked state, the kernel removes them from the run queue, saves all the processor registers into the thread structure, and then make a scheduling decision to select some other process to run from the run queue. The kernel changes the state of the selected task from Ready to Running and loads its registers from the task structures into the CPU registers.
The process of switching the CPU between two tasks is called a Context Switch. Context switches are expensive for two reasons. First, there is overhead to save the state (i.e., CPU registers) of the outgoing process, select the next process to run, and load the state of the incoming task. Second, even though we are saving all the state needed to resume a process, modern processors have several caches (e.g., data and instruction caches, the translation look aside buffer, etc.) that help an application run more quickly. As the application runs, these caches are filled with instructions or data that are related to the executing process. When a new task is placed on a CPU, the contents of these caches are no longer related to the running process, and either need to be cleared by the OS, or need to be replaced by the new process as it executes.
Once whatever causes the task to be blocked is resolved, the kernel changes the state of the task from Blocked to Ready, and places the task struct onto the run queue so it can be run the next time there is a scheduling decision to be made.
A task may also transition from the Running to the Ready state without going through the Blocked state. Some tasks may run for a really long time without doing any I/O. This can cause a problem for other tasks that are constantly blocking and doing get their fair share of the processor. To handle this, all systems have hardware timers, where the kernel can configure the timer to cause an interrupt at some future time. When the interrupt occurs, the kernel stops the current task, and makes a scheduling decision to context switch to some other task. This is called Preemption, where the kernel stops, or Preempts a task to run another one.