Memory Management Page Faults
Contents
This chapter describes page faults, what they are, various types, how they work and how they allow virtual address spaces that are much larger than physical memory.
14.6. Memory Management Page Faults#
There are 3 basic types of page faults:
File backed page faults
Anonymous page faults
Copy On Write page faults
14.6.1. Page Faulting#
In the previous section you saw how the MMU in a Pentium-like CPU determines whether a memory access will succeed:
if the top-level entry has P=1
and is(read) or W=1
and is(supervisor) or U=1:
if the 2nd-level entry has P=1
and is(read) or W=1
and is(supervisor) or U=1:
use translated address.
If translation fails at any one of the six possible points above (P, W, or U at each level) then a page fault is generated.
14.6.1.1. Page Faults#
A page fault is a special form of exception that has the following two characteristics: first, it is generated when an address translation fails, and second, it occurs in the middle of an instruction, not after it is done, so that the instruction can be continued after fixing the problem which caused the page fault. Typical information that the MMU passes to the page fault handler is:
The instruction address when the page fault occurred. (this is the return address pushed on the stack as part of the exception handling process)
The address that caused the page fault
Whether the access attempt was a read or a write
Whether the access was attempted in user or supervisor mode
After the page fault handler returns, the instruction that caused the fault resumes, and it retries the memory access that caused the fault in the first place.
Note
15 Many of the examples in this section are illustrated using Linux, as the source code is readily available, but same principles (although not details) hold true for other modern OSes such as Windows, Mac OS X, or Solaris.
In addition, keep in mind that the virtual memory map for a process is a software concept, and will almost certainly differ between two unrelated operating systems. In contrast, the page table structure is defined by the CPU itself, and must be used in that form by any operating system running on that CPU.
A single instruction can cause multiple, different page faults, of which there are two different types:
Instruction fetch: A fault can occur when the CPU tries to fetch the instruction at a particular address. If the instruction “straddles” a page boundary (i.e., a 6-byte instruction that starts 2 bytes before the end of a page) then you could (in the worst case) get two page faults while trying to fetch an instruction.
Memory access: Once the instruction has been fetched and decoded, it may require one or more memory accesses that result in page faults. These memory accesses include those to the stack (e.g., for CALL and RET instructions) in addition to load and store instructions. As before, accessing memory that straddles a page boundary will result in additional faults.
14.6.1.2. Process Address Space, Revisited#
How does the OS know how to handle a page fault? By examining its internal memory map for a process. We’ve talked briefly about process memory maps earlier, but now we will look in more detail at a specific one, from a fairly recent (kernel 2.6 or 3.0) 32-bit Linux system. A more thorough description of the Linux memory layout can be found here.
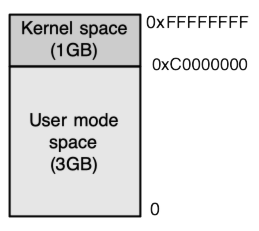
Fig. 14.22 Top 1GB is the Kernel address space and bottom 3GB is the user address space.#
In earlier chapters we saw how simple operating systems may use separate portions of the address space for programs and for the operating system. The same approach is often used in dividing up the virtual address space in more complex operating systems, as seen in the 32-bit Linux memory map in Fig. 14.22. In recent Linux versions running on 32-bit Intel-compatible CPUs, the kernel “owns” the top 1GB, from virtual address 0xC0000000 to 0xFFFFFFFF, and all kernel code, data structures, and temporary mappings go in this range.
The kernel must be part of every address space, so that when exceptions like system calls and page faults change execution from user mode to supervisor mode, all the kernel code and data needed to execute the system call or page fault handler are already available in the current virtual memory map[^8] This is the primary use for the U bit in the page table—by setting the U bit to zero in any mappings for operating system code and data, user processes are prevented from modifying the OS or viewing protected data.
Here is the memory map of a very simple process[^9], as reported in
/proc/<pid>/maps:
08048000-08049000 r-xp 00000000 08:03 4072226 /tmp/a.out
08049000-0804a000 rw-p 00000000 08:03 4072226 /tmp/a.out
0804a000-0804b000 rw-p 00000000 00:00 0 [anon]
bffd5000-bfff6000 rw-p 00000000 00:00 0 [stack]
The memory space has four segments:
**08048000** (one page) - read-only, executable, mapped from file *a.out*
**08049000** (one page) - read/write, mapped from file *a.out*
**0804a000** (one page) - read/write, "anonymous"
**bffd5000-bfff6000** (33 4KB pages) - read/write, "stack"
Where does this map come from? When the OS creates the new address space
in the exec() system call, it knows it needs to create a stack, but
the rest of the information comes from the executable file itself:
$ objdump -h a.out
a.out: file format elf32-i386
Idx Name Size VMA LMA File off Algn
0 .text 00000072 08048094 08048094 00000094 2**2
CONTENTS, ALLOC, LOAD, READONLY, CODE
1 .rodata 000006bd 08048108 08048108 00000108 2**2
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .data 00000030 080497c8 080497c8 000007c8 2**2
CONTENTS, ALLOC, LOAD, DATA
3 .bss 00001000 08049800 08049800 000007f8 2**5
ALLOC
$
Executable files on Linux are stored in the ELF format (Executable and Linking Format), and include a header that describes the file to the OS; the information above came from this header. Looking at the file, the following sections can be seen:
`0 ... x93` various header information
`00000094 - 00000107` ".text" program code
`00000108 - 000007c7` ".rodata" read/only data (mostly strings)
`000007c8 - 000007e7` ".data"' initialized writable data
(no data) ".bss"' zero-initialized data
The BSS section corresponds to global variables initialized to zero. Since the BSS section is initialized to all zeros, there is no need to store its initial contents in the executable file. Instead, the exec() system call allocate anonymous memory for any BSS sections thereby reducing the actual size of executable files on storage.
14.6.1.2.1. Executable file and process address space#
Here you can see the relationship between the structure of the executable file and the process address space created by the kernel when it runs this executable. One page (08048xxx) is used for read-only code and data, while two pages (08049xxx and 0804Axxx) are used for writable data.
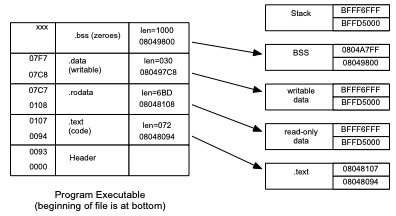
Fig. 14.23 Relationship of executable file header to memory map structure#
14.6.1.3. Page Faults in the Kernel#
Although common in the past, modern Windows and Linux systems rarely seem to crash due to driver problems. (Although my Mac panics every month or two.) If you ever develop kernel drivers, however, you will become very familiar with them during the debug phase of development.
What happens if there is a page fault while the CPU is running kernel code in supervisor mode? It depends.
If the error is due to a bug in kernel-mode code, then in most operating systems the kernel is unable to handle it. In Linux the system will display an “Oops” message, as shown below, while in Windows the result is typically a “kernel panic”, which used to be called a Blue Screen of Death. Most of the time in Linux the process executing when this happens will be terminated, but the rest of the system remains running with possibly reduced functionality.
[ 397.864759] BUG: unable to handle kernel NULL pointer dereference at
0000000000000004
[ 397.865725] IP: [<ffffffffc01d1027>] track2lba+0x27/0x3f [dm_vguard]
[ 397.866619] PGD 0
[ 397.866929] Oops: 0000 [#1] SMP
[ 397.867395] Modules linked in: [...]
[ 397.872730] CPU: 0 PID: 1335 Comm: dmsetup Tainted: G OE 4.6.0 #3
[ 397.873419] Hardware name: QEMU Standard PC (i440FX + PIIX, 1996), BIOS ...
[ 397.874487] task: ffff88003cd10e40 ti: ffff880037080000 task.ti: ffff88003708
[ 397.875375] RIP: 0010:[<ffffffffc01d1027>] [<ffffffffc01d1027>] track2lba+0x27
[ 397.876509] RSP: 0018:ffff880037083bd0 EFLAGS: 00010282
[ 397.877193] RAX: 0000000000000001 RBX: 0000000000003520 RCX: 0000000000000000
[ 397.878085] RDX: 0000000000000000 RSI: 0000000000003520 RDI: ffff880036bd70c0
[ 397.879016] RBP: ffff880037083bd0 R08: 00000000000001b0 R09: 0000000000000000
[ 397.879912] R10: 000000000000000a R11: f000000000000000 R12: ffff880036bd70c0
[ 397.880763] R13: 00000000002e46e0 R14: ffffc900001f7040 R15: 0000000000000000
[ 397.881618] FS: 00007f5767938700(0000) GS:ffff88003fc00000(0000)
[ 397.915186] CS: 0010 DS: 0000 ES: 0000 CR0: 0000000080050033
[ 397.932122] CR2: 0000000000000004 CR3: 000000003d3ea000 CR4: 00000000000406f0
[ 397.949459] Stack:
... stack contents and backtrace omitted ...
But what about addresses passed by the user in a system call? For
example, what if the memory address passed to a read
system call has been paged out, or not instantiated yet? It turns out
that the same page faulting logic can be used in the kernel, as
well—the first access to an unmapped page will result in a fault, the
process will be interrupted (in the kernel this time, rather than in
user-space code), and then execution will resume after the page fault is
handled.
But what if the user passes a bad address? We can’t just kill the
process partway through the system call, because that would risk leaving
internal operating system data structures in an inconsistent state. (Not
only that, but the POSIX standard requires that system calls return the
EFAULT error in response to bad addresses, not exit.) Instead, all code
in the Linux kernel which accesses user-provided memory addresses is
supposed to use a pair of functions,
copy_from_user and copy_to_user, which check that the user-provided
memory region is valid for user-mode access[^11].
In very early versions of Linux the kernel ran in a separate address
space where virtual addresses mapped directly to physical addresses, and
so these functions actually interpreted the page tables to translate
virtual addresses to physical (i.e. kernel virtual) addresses, which was
slow but made it easy to return an error if an address was bad. Newer
Linux versions map the kernel and its data structures into a predefined
region of each each process virtual address space, making these functions
much faster but more
complicated. The speedup is because there is no longer any need to
translate page tables in software; instead the two
copy_*_user functions just perform a few checks
and then a memcpy. More complicated because if it fails
we don’t find out about it in either of these functions, but rather in
the page fault handler itself. To make this work, if the page fault (a)
occurs in kernel mode, and (b) the handler can’t find a translation for
the address, it checks to see if the fault occurred while executing the
copy_from_user or copy_to_user functions, and if so it performs some
horrible stack manipulation to cause that function to return an error
code[^12].
But what if a page fault occurs in the kernel outside of these two
functions? That should never happen, because kernel structures are
allocated from memory that’s already mapped in the kernel address space.
In other words it’s a bug, just like the bugs that cause segmentation
faults in your C programs. And just like those bugs it causes a crash,
resulting in an error message such as the one shown above. If the kernel was running in a process context
(e.g. executing system call code) then the currently-running process
will be killed. This behavior is really not safe because its likely some
corruption of kernel data structures and not likely cause be the process
itself. However, it does prevent the whole system from crashing.
If this occurs during an interrupt the system will crash.
The equivalent in Windows is called a Blue Screen of Death
(although they changed the color several versions back); since almost
all Windows kernel code executes in interrupt context, these errors
always result in a system crash.
14.6.1.4. copy-on-write page faults#
In all the cases you’ve seen so far, page sharing has been used to share read-only pages—these are intrinsically safe to share, because processes are unable to modify the pages and thereby affect other processes. But, can writable pages be shared safely? The answer is yes, but it has to be done carefully.
First, some background on why this is important. The Unix operating
system uses two system calls to create new processes and execute
programs: fork() and exec(). fork() makes a copy of the current
process[^16], while exec(file) replaces the address space of the
current process with the program defined by file and begins executing
that program at its designated starting point.
UNIX uses this method because of an arbitrary choice someone made 40 years ago; there are many other ways to do it, each of them with their own problems. However this is how UNIX works, and we’re stuck with it, so it’s important to be able to do it quickly.
In early versions of Unix, fork() was implemented by literally copying
all the writable sections (e.g., stack, data) of the parent process
address space into the child process address space. After doing all this
work, most (but not all) of the time, the first thing the child process
would do is to call exec(), throwing away the entire contents of the
address space that were just copied. It’s bad enough when the shell does
this, but even worse when a large program (e.g. Chrome) tries to execute
a small program (e.g. /bin/ls) in a child process.
We’ve already seen how to share read-only data, but can we do anything about writable data? In particular, data which is writable, but isn’t actually going to be written?
A quick inspection of several Firefox and Safari instances (using pmap on Linux and vmmap on OS X) indicates that a browser with two or three open tabs can easily have over 300MB of writable address space[^17]. When fork is executed these writable pages can’t just be given writable mappings in the child process, or changes made in one process would be visible in the other. In certain cases (i.e., the stack) this mutual over-writing of memory would almost certainly be disastrous.
However in practice, most of these writable pages won’t be written to again. In fact, if the child process only executes a few lines of code and then calls exec{.uri}, it may only modify a handful of pages before its virtual address space is destroyed and replaced with a new one.
Copy-on-write is in fact a widely-used strategy in computer systems. It is effectively a “lazy” copy, doing only the minimal amount of work needed and reducing both the cost of copying and the total space consumed. Similar copy-on-write mechanisms can be seen in file systems, storage devices, and some programming language runtime systems.
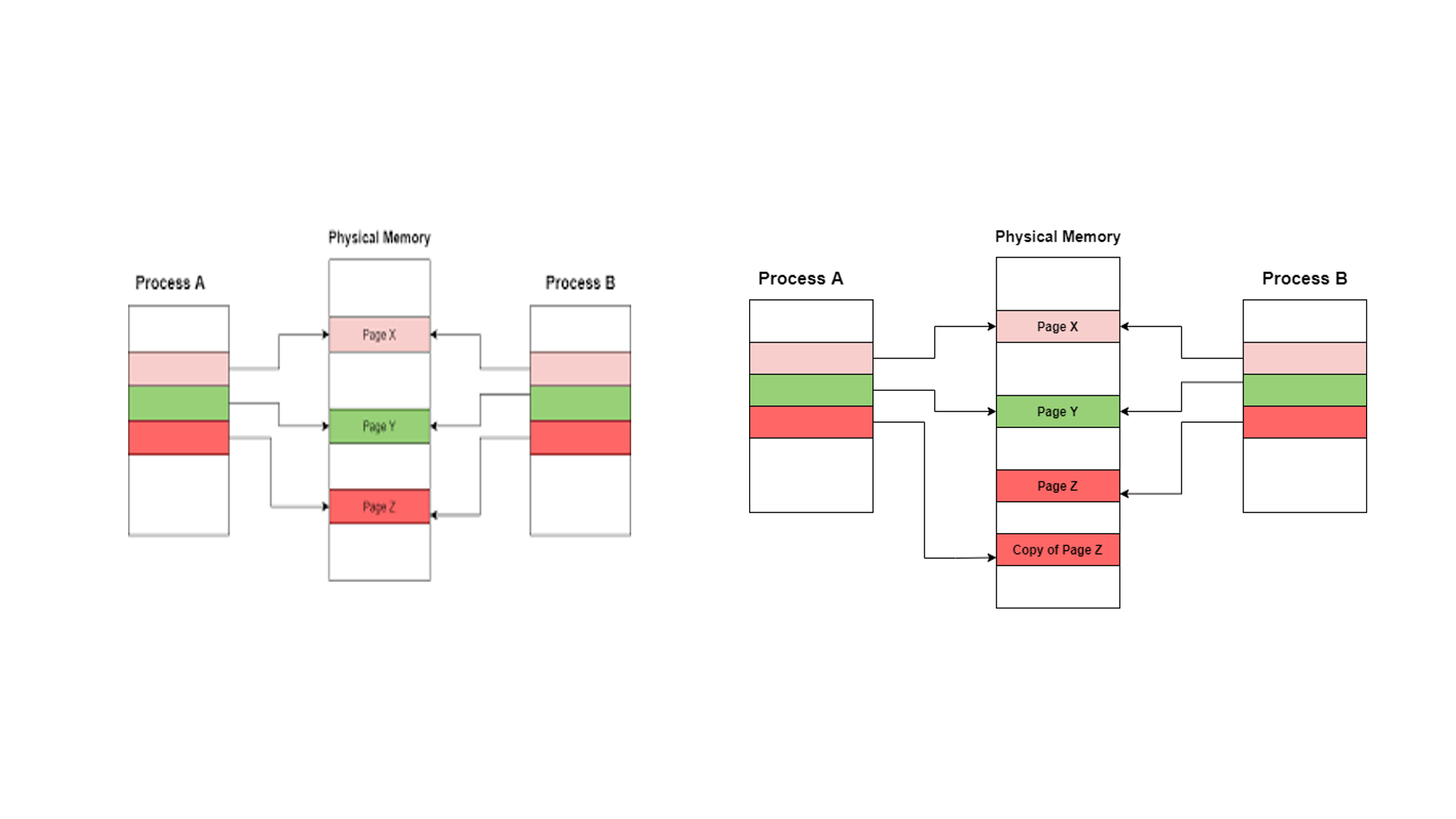
Fig. 14.24 Copy On Write after fork()#
Linux uses a technique called copy-on-write to eliminate the need to copy most of this memory. When a child process is created in the fork{.uri} system call, its address space shares not only the read-only pages from the parent process, but the writable pages as well. To prevent the two processes from interfering with each other, these pages are mapped read-only, resulting in a page fault whenever they are accessed by either process, but flagged as copy-on-write in the kernel memory map structures. This results in a page fault when either process tries to write to one of these pages; the page fault handler then “breaks” the sharing for that page, by allocating a new page, copying the old one, and mapping a separate page read-write in each of the processes.